
# 推导一下逻辑回归的损失函数,并解释其含义。
设
最后,通过扫描样本,迭代下述公式可求得参数:
- 来源:https://zhuanlan.zhihu.com/p/74874291
# 在广告LR模型中,为什么要做特征组合?
逻辑回归模型有诸多优势,它的本质是一个对数线性模型,实现简单,易于并行,大规模扩展方便,迭代速度快,可解释性比较强,预测输出在0与1之间,恰好契合概率模型。
但是线性模型难以刻画非线性关系,特征组合正好可以加入非线性表达,增加了模型的表达能力。
此外,在广告的逻辑回归模型中,基本特征即单特征可认为是用于全局建模,而组合特征则更为个性化地精细表达。因为在这种超大规模离散LR中,仅仅对全局建模会对部分用户有偏,对每一用户建模又数据不足易过拟合的同时带来模型数量爆炸,所以基本特征+组合特征兼顾了全局和个性化。
从统计的角度解释,基本特征仅仅是真实特征分布在低维空间的映射,不足以描述真实分布,加入组合特征是为了在更高维空间拟合真是分布,使得预测更为准确。
- 来源:https://www.zhihu.com/question/34271604
# 为什么 LR 模型要使用 sigmoid 函数,背后的数学原理是什么?为什么不用其他函数?
关键词:指数分布族、canonical link function
https://www.zhihu.com/question/23666587 https://www.zhihu.com/question/41647192 https://zhuanlan.zhihu.com/p/74874291
# 为什么LR可以用来做点击率预估?
https://www.zhihu.com/question/23652394
# 满足什么样条件的数据用LR最好?换句话说,为了LR工作的更好,要对数据做一些什么处理?
https://www.zhihu.com/question/23652394/answer/91410449
# 逻辑斯蒂回归能否解决非线性分类问题?
https://www.zhihu.com/question/29385169
# 给一个有m个样本n维特征的数据集,LR算法中梯度的维度是多少?
# 逻辑回归损失函数为什么使用最大似然估计而不用最小二乘法?
https://www.zhihu.com/question/65350200 https://www.zhihu.com/question/23817253
# 如何求解逻辑回归的参数?
https://zhuanlan.zhihu.com/p/74874291
# SVM 和 LR 有什么异同?分别在什么情况下使用?
- 从目标函数来看,区别在于逻辑回归采用的是logloss,svm采用的是hinge loss。
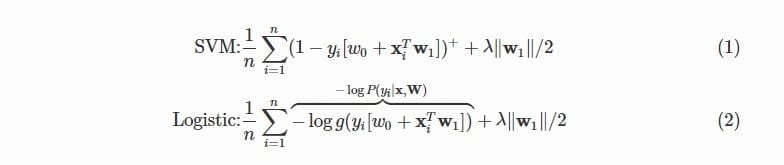
这两个损失函数的目的都是增加对分类影响较大的数据点的权重,减少与分类关系较小的数据点的权重。SVM的处理方法是只考虑support vectors,也就是和分类最相关的少数点,去学习分类器。而逻辑回归通过非线性映射,大大减小了离分类平面较远的点的权重,相对提升了与分类最相关的数据点的权重。
逻辑回归相对来说模型更简单,好理解,实现起来特别是大规模线性分类时比较方便。而SVM的理解和优化相对来说复杂一些。但是SVM的理论基础更加牢固,有一套结构化风险最小化的理论基础,
SVM转化为对偶问题后,分类只需要计算与少数几个支持向量的距离,这个在进行复杂核函数计算时优势很明显,能够大大简化模型和计算量。
如果一个问题的异常点较多无法剔除,首先LR中因为每个样本都对最终Loss有贡献,最大似然后会自动压制异常的贡献;SVM+软间隔却对异常比较敏感,因为其训练只需要支持向量,有效样本本来就不高,一旦被干扰,预测结果难以预料
对非线性问题的处理方式不同,LR主要靠特征构造,必须组合交叉特征,特征离散化。SVM也可以这样,还可以通过kernel。
在训练集较小时,SVM较适用,而LR需要较多的样本。
SVM的损失函数就自带正则,(损失函数中的1/2||w||^2项),这就是为什么SVM是结构风险最小化算法的原因,而LR必须另外在损失函数上添加正则项。
https://www.zhihu.com/question/21704547 https://www.zhihu.com/question/24904422 https://www.zhihu.com/question/26768865
# 为什么LR不适合用MSE?
https://zhuanlan.zhihu.com/p/74874291
# 为什么逻辑回归需要先对特征离散化?
- 离散后稀疏向量内积乘法运算速度更快,计算结果也方便存储,容易扩展;
- 离散后的特征对异常值更具鲁棒性,如 age>30 为 1 否则为 0,对于年龄为 200 的也不会对模型造成很大的干扰;
- LR 属于广义线性模型,表达能力有限,经过离散化后,每个变量有单独的权重,这相当于引入了非线性,能够提升模型的表达能力,加大拟合;
- 离散后特征可以进行特征交叉,提升表达能力,由 M+N 个变量编程 M*N 个变量,进一步引入非线形,提升了表达能力;
- 特征离散后模型更稳定,如用户年龄区间,不会因为用户年龄长了一岁就变化;
总的来说,特征离散化以后起到了加快计算,简化模型和增加泛化能力的作用。
https://zhuanlan.zhihu.com/p/74874291
# 并行LR的实现
https://zhuanlan.zhihu.com/p/74874291
# 逻辑回归(Logistic regression)在金融领域有什么应用呢?
https://www.zhihu.com/question/328007709/answer/720158995