
# 请解释一下损失函数的定义
损失函数(loss function)是用来估量模型的预测值f(x)与真实值
前面的均值函数表示的是经验风险函数,
# 请说说你对逻辑回归损失函数的理解
有些人可能觉得逻辑回归的损失函数就是平方损失,其实并不是。平方损失函数可以通过线性回归在假设样本是高斯分布的条件下推导得到,而逻辑回归得到的并不是平方损失。在逻辑回归的推导中,它假设样本服从伯努利分布(0-1分布),然后求得满足该分布的似然函数,接着取对数求极值等等。而逻辑回归并没有求似然函数的极值,而是把极大化当做是一种思想,进而推导出它的经验风险函数为:最小化负的似然函数(即
Log损失函数的标准形式:
logistic回归的
# 请说说你对平方损失函数的理解。
最小二乘法是线性回归的一种,OLS将问题转化成了一个凸优化问题。在线性回归中,它假设样本和噪声都服从高斯分布(为什么假设成高斯分布呢?其实这里隐藏了一个小知识点,就是中心极限定理,可以参考【central limit theorem】),最后通过极大似然估计(MLE)可以推导出最小二乘式子。最小二乘的基本原则是:最优拟合直线应该是使各点到回归直线的距离和最小的直线,即平方和最小。换言之,OLS是基于距离的,而这个距离就是我们用的最多的欧几里得距离。为什么它会选择使用欧式距离作为误差度量呢(即Mean squared error, MSE),主要有以下几个原因:
- 简单,计算方便;
- 欧氏距离是一种很好的相似性度量标准;
- 在不同的表示域变换后特征性质不变。
平方损失(Square loss)的标准形式如下:
而在实际应用中,通常会使用均方差(MSE)作为一项衡量指标,公式如下:
上面提到了线性回归,这里额外补充一句,我们通常说的线性有两种情况,一种是因变量y是自变量x的线性函数,一种是因变量y是参数α的线性函数。在机器学习中,通常指的都是后一种情况。
# 请谈谈你对指数损失函数的了解。
学过Adaboost算法的人都知道,它是前向分步加法算法的特例,是一个加和模型,损失函数就是指数函数。在Adaboost中,经过m此迭代之后,可以得到
# 请谈谈你对Hinge合页损失函数的了解。
线性支持向量机学习除了原始最优化问题,还有另外一种解释,就是最优化以下目标函数:
接下来证明线性支持向量机原始最优化问题: $$ \underset{w,b,\xi}{\min}\ \frac{1}{2}||w||^2+C\sum_{i=1}^N{\xi _i} $$ $$ s.t.\ \ y_i\left( w·x_i+b \right) \geqslant 1-\xi _i\ ,\ i=1,2,···,N $$ $$ \xi _i\geqslant 0,\ i=1,2,···\mathrm{,}N $$ 等价于最优化问题
先令
合页损失函数图像如图所示,横轴是函数间隔
图中还画出了0-1损失函数,可以认为它是一个二类分类问题的真正的损失函数,而合页损失函数是0-1损失函数的上界。由于0-1损失函数不是连续可导的,直接优化其构成的目标函数比较困难,可以认为线性支持向量机是优化由0-1损失函数的上界(合页损失函数)构成的目标函数。这时的上界损失函数又称为代理损失函数(surrogate function)。
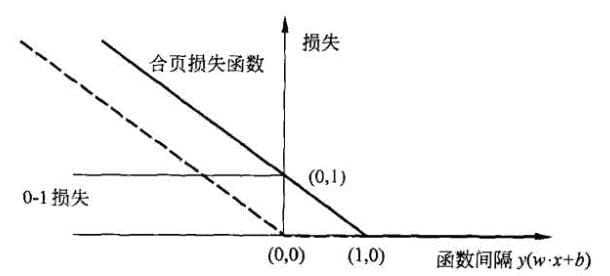 图中虚线显示的是感知机的损失函数
图中虚线显示的是感知机的损失函数
# 请你对逻辑斯谛回归和SVM的损失函数进行一下对比。
我们先来看一下带松弛变量的 SVM 和正则化的逻辑回归它们的损失函数: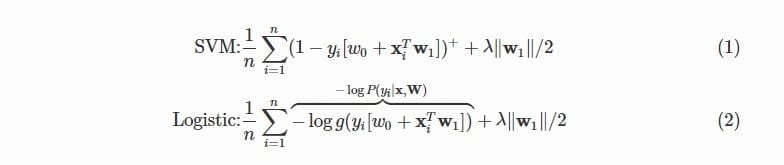 其中
其中
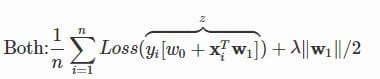
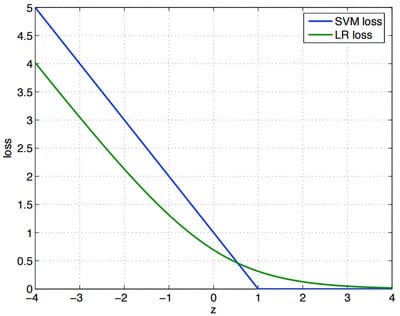 这两个损失函数的目的都是增加对分类影响较大的数据点的权重,减少与分类关系较小的数据点的权重。SVM的处理方法是只考虑support vectors,也就是和分类最相关的少数点,去学习分类器。而逻辑回归通过非线性映射,大大减小了离分类平面较远的点的权重,相对提升了与分类最相关的数据点的权重,两者的根本目的都是一样的。
这两个损失函数的目的都是增加对分类影响较大的数据点的权重,减少与分类关系较小的数据点的权重。SVM的处理方法是只考虑support vectors,也就是和分类最相关的少数点,去学习分类器。而逻辑回归通过非线性映射,大大减小了离分类平面较远的点的权重,相对提升了与分类最相关的数据点的权重,两者的根本目的都是一样的。
svm考虑局部(支持向量),而logistic回归考虑全局,就像大学里的辅导员和教师间的区别。
辅导员关心的是挂科边缘的人,常常找他们谈话,告诫他们一定得好好学习,不要浪费大好青春,挂科了会拿不到毕业证、学位证等等,相反,对于那些相对优秀或者良好的学生,他们却很少去问,因为辅导员相信他们一定会按部就班的做好分内的事;而大学里的教师却不是这样的,他们关心的是班里的整体情况,大家是不是基本都理解了,平均分怎么样,至于某个人的分数是59还是61,他们倒不是很在意。
总结:
- LR采用log损失,SVM采用合页损失。
- LR对异常值敏感,SVM对异常值不敏感。
- 在训练集较小时,SVM较适用,而LR需要较多的样本。
- LR模型找到的那个超平面,是尽量让所有点都远离他,而SVM寻找的那个超平面,是只让最靠近中间分割线的那些点尽量远离,即只用到那些支持向量的样本。
- 对非线性问题的处理方式不同,LR主要靠特征构造,必须组合交叉特征,特征离散化。SVM也可以这样,还可以通过kernel。
- svm 更多的属于非参数模型,而logistic regression 是参数模型,本质不同。其区别就可以参考参数模型和非参模型的区别
那怎么根据特征数量和样本量来选择SVM和LR模型呢?Andrew NG的课程中给出了以下建议:
- 如果Feature的数量很大,跟样本数量差不多,这时候选用LR或者是Linear Kernel的SVM
- 如果Feature的数量比较小,样本数量一般,不算大也不算小,选用SVM+Gaussian Kernel
- 如果Feature的数量比较小,而样本数量很多,需要手工添加一些feature变成第一种情况。(LR和不带核函数的SVM比较类似。)
# 对于逻辑回归,为什么说平方损失函数是非凸的?
https://www.zhihu.com/question/264396874
# 如何把SVM的推导和损失函数联系起来?
https://www.zhihu.com/question/62881491
# 神经网络如何设计自己的loss function,如果需要修改或设计自己的loss,需要遵循什么规则?
https://www.zhihu.com/question/59797824/answer/203696473
# softmax和cross-entropy是什么关系?
https://www.zhihu.com/question/294679135
# 神经网络的损失函数为什么是非凸的?
https://www.zhihu.com/question/265516791
# 深度学习中有哪些常用损失函数(优化目标函数)?
https://www.zhihu.com/question/317383780/answer/631866229
# 神经网络中,设计loss function有哪些技巧?
https://www.zhihu.com/question/268105631/answer/333601828
# 神经网络中,为何不直接对损失函数求偏导后令其等于零,求出最优权重,而要使用梯度下降法(迭代)计算权重?
https://www.zhihu.com/question/267021131
# 在用交叉熵损失函数时,只希望惩罚 0.4~0.6 这样模糊的值,应该怎么改?
https://www.zhihu.com/question/366389643/answer/976521815