
# 简述一下 Adaboost 的权值更新方法
对提升方法来说,有两个问题需要回答:
- 在每一轮如果改变训练数据的权值或概率分布;
- 如何将弱分类器组合成一个强分类器。
对于第一个问题,AdaBoost的做法是,提高那些被前一轮弱分类器错误分类样本的权值,而降低那些被正确分类样本的权值。这样一来,那些没有得到正确分类的数据,由于其权值的加大而受到后一轮的弱分类器的更大关注,于是,分类问题就被一系列的弱分类器“分而治之”。
至于第二个问题,即弱分类器的组合,AdaBoost采取加权多数表决的方法。具体地,加大分类误差率小的弱分类器的权值,使其在表决中起较大的作用,减小分类误差率较大的弱分类器的权值,使其在表决中起较小的作用。
AdaboostBoost的算法的框架如下图所示
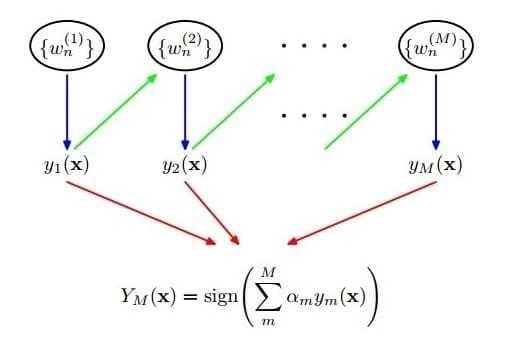 具体来说,整个AdaBoost算法包括以下三个步骤:
具体来说,整个AdaBoost算法包括以下三个步骤:
- 1)初始化训练样本的权值分布。 如果有N个样本,则每一个训练样本最开始时都被赋予相同的权值:
- 2)训练弱分类器。具体训练过程中,如果某个样本已经被准确地分类,那么在构造下一个训练集中,它的权值就会被降低;相反,如果某个样本点没有被准确地分类,那么它的权值就得到提高。然后,权值更新过的样本被用于训练下一个分类器,整个训练过程如果迭代地进行下去,使得分类器在迭代过程中逐步改进。
- 3)将各个训练得到的弱分类器组合成强分类器。各个弱分类器的训练过程结束后,加大分类误差率小的弱分类器的权重,使其在最终的分类函数中起着较大的决定作用,而降低分类误差率大的弱分类器的权重,使其在最终的分类函数中起着较小的决定作用。换言之,误差率低的弱分类器在最终分类器中权重较大,否则较小。得到最终分类器。
# 推导一下Adaboost的样本权重更新公式
假定给定一个二类分类的训练数据集
步骤一:首先,初始化训练数据的权值分布。
步骤二:在每一轮
- 1)使用当前权值分布为
- 2)计算上一步得到的基分类器
这里 - 3)计算
- 4)更新训练数据集的权值分布为下一轮作准备
其中
我们也可以写成:
$$w_{m+1,i} = \left{\begin{matrix} \frac{w_{mi}}{Z_m}e^{-a_m}\ , & G_m\left(x_i\right)=y_i\ \frac{w_{mi}}{Z_m}e^{a_m}\ , & G_m\left(xi\right)\ne y_i\ \end{matrix}\right. $$
由此可知,被基本分类器
步骤三:将上一步得到的基分类器根据权重参数线性组合
# 训练过程中,为何每轮训练一直存在分类错误的问题,整个Adaboost却能快速收敛?
每轮训练结束后,AdaBoost 会对样本的权重进行调整,调整的结果是越到后面被错误分类的样本权重会越高。而后面的分类器为了达到较低的带权分类误差,会把样本权重高的样本分类正确。这样造成的结果是,虽然每个弱分类器可能都有分错的样本,然而整个 AdaBoost 却能保证对每个样本进行正确分类,从而实现快速收敛。
# Adaboost 的优缺点?
优点:
- 能够基于泛化性能相当弱的的学习器构建出很强的集成,不容易发生过拟合。
缺点:
- 对异常样本比较敏感,异常样本在迭代过程中会获得较高的权值,影响最终学习器的性能表现。
# AdaBoost 与 GBDT 对比有什么异同?
相同:
- 都是 Boosting 家族成员,使用弱分类器;
- 都使用前向分布算法;
不同:
- 迭代思路不同:Adaboost 是通过提升错分数据点的权重来弥补模型的不足(利用错分样本),而 GBDT 是通过算梯度来弥补模型的不足(利用残差);
- 损失函数不同:AdaBoost 采用的是指数损失,GBDT 使用的是绝对损失或者 Huber 损失函数;