# 在处理数值特征过程中,如何处理缺失值?某新物料的后验指标未知,如何填充?某男性新用户对“体育”这个分类的喜好程度未知,如何填充?
如果某条样本x中某个实数特征F的取值缺失,最常规的作法就是拿所有样本在特征F上的均值(Mean)或中位数(Median)代替。当然我们可以做得更精细一些。比如来了一个男性新用户,他对"体育"类视频的CTR未知,我们可以拿所有男性用户对"体育"视频的CTR来填充这一缺失值,相比于用全体用户的均值来填充更有针对性。 但是如果我们又知道了该新用户的年龄,难道又要根据"性别+年龄"的组合重新划分人群计算均值?那样岂不是太麻烦了。一个更合理的作法是训练一个模型来预测缺失值。比如对于新用户,我们可以构建一个模型,利用比较容易获得的人口属性(比如性别、年龄等)预测新用户对某个内容分类、标签的喜爱程度(比如对某类内容的CTR)。再比如对于新物料,我们可以训练一个模型,利用物料的静态画像(比如分类、标签、品牌、价位)预测它的动态画像(CTR、平均观看时长、平均销售额等)。 当然,如果我们选择对数值特征离散化,处理缺失值就更容易了。我们可以在分桶时,为每个特征都增加一个叫"未知"的桶,专门用来映射该特征的缺失值。
# 如何对数值特征进行标准化?对观看次数、观看时长这样的特征,如何做标准化?
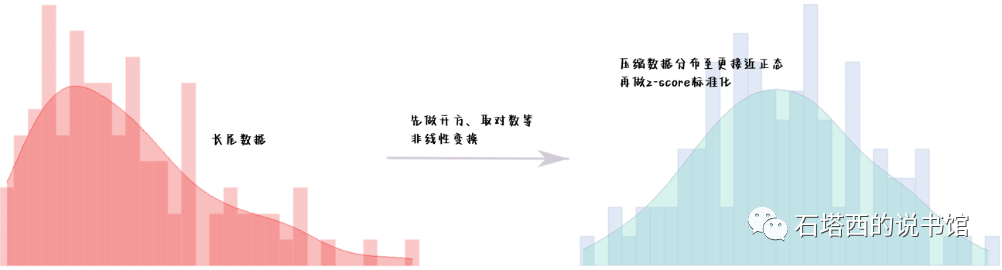
标准化的目的是将不同量纲、不同取值范围的数值特征都压缩到同一个数值范围内,使它们彼此可比。最常用的标准化是z-score标准化,如公式(2-4)所示。
- x是某条样本在特征F的原始取值。
、
值得一提的是,推荐系统中经常会用到一些长尾分布的特征,比如观看次数,大多数用户一天观看不到100个视频,但是也有个别重度用户一天就要刷1000个视频。这种情况下,直接统计出来的
# 某个物料曝光2次,被点击1次,如何计算它的CTR?
推荐系统中经常要计算各种比率作为特征,比如点击率、点赞率、购买率、复购率等。计算这些比率时,我们经常遇到的一个问题就是样本太少,导致计算结果不可信。比如计算一件商品,只被曝光了一次并被购买了,由此我们就说它的购买率是100%,从而认定它是爆款,应该大力推荐,显然这是站不住脚的。为克服小样本的负面影响,提高计算结果的置信水平,我们可以采用"威尔逊区间平滑":
- z是一个超参,代表对应某个置信水平的z-score。比如当我们希望计算结果有95%的置信水平时,z应该等于1.96。
- p是用简单方法计算出的比率。比如当p代表点击率时,就是拿点击样本数除以曝光样本数。
- n是样本数量。从公式中可以看出,当n非常大时,
另一种消偏是为了抹平不同细分领域天然存在的偏差,使不同细分领域得到的统计指标尽量公平可比。假设有A、B两篇文章,经过充分曝光后,A的点击率是10%,B的点击率是8%,是否一定说明A比B更受欢迎,接下来应该大力推荐?答案是否定的。仔细观察我们发现,文章A一般都展示在比较靠前、显眼的位
置,而文章B的展示位置一般都在不醒目的边边角角。众所周知,展示位置对用户是否点击起着至关重要的作用。尽管文章B的位置不好,但是其点击率与占据好位置的文章A不相上下,这不正好说明B更受欢迎吗?下次如果我们能将B放在更引人注目的位置上,它的消费数据会更加出色。
至于为什么B那么优秀却未能显示在好位置,其中一个可能的原因就是使用CTR来衡量物料的受欢迎程度,而CTR没有考虑不同显示位置的吸引眼球的能力不同,从而使展示在较差位置上的优质物料没有出头之日。至于解决方法,另一种消偏的思路,就是用CoEC(ClickOver Expected Click)代替CTR衡量物料的受欢迎程度。CoEC的计算:
- i表示第i次曝光样本,Ν是样本总数。
CoEC消除了不同展示位置带来的偏差因素,从而更能公平地反映各物料的受欢迎程度。
# 如何对数值型数据进行分桶?
在推荐模型中,使用类别特征具有能更好反映非线性关系、便于存储与计算等多方面优势,因此在实践中,我们更喜欢将实数特征离散成类别特征。离散方法就是分桶,即将实数特征的值域划分为若干区间,又称为"桶",看实数特征落进哪个桶,就以那个桶的桶号作为类别特征值。比如,某用户在最近一小时看了5个视频,如果用实数特征描述,特征是"最近1小时看的视频数",特征值是5。而如果离散成类别特征,整个特征可以表示成"last1hour_0_10"这个字符串,表示该用户在最近1小时看的视频数在0~10之间。 分桶有三种实现方式:
- 等宽分桶:即将特征值域平均划分为了N等份,每份算一个桶。
- 等频分桶:将整个值域的N个分位数(Percentile)作为各桶的边界,保证落入各个桶的样本个数大致要相等。
- 模型分桶:对实数特征F分桶,要分为两个阶段。第1阶段,单独拿特征F与目标值拟合一棵简单的决策树。第2阶段才进行分桶,将某个特征中F的实数取值f喂进决策树,f最终落进的那个叶子节点的编号就是f的离散化结果。