# 请简述向量化召回的基本链路,如何统一的建模框架来解释向量化召回?
所谓向量化召回,就是将召回问题,建模成向量空间内的近邻搜索问题。假设召回问题中包含两类实体Q和T
- 如果Q是用户,T是物料,给用户直接找他喜欢的物料,就是user-to-item召回(简称U2I);
- 如果Q和T都是物料,那就是item-to-item召回(简称I2I),用于给用户找与他喜欢的物料相似的其他物料,比如"看了又看"场景;
- 如果Q和T都是用户,那就是user-to-user-to-item召回(简称U2U2I),先给当前用户查找与他相似的用户,再把相似用户喜欢的东西推荐给当前用户。
向量化召回的基本套路如下:
- 第一步,训练一个模型
- 第二步,将
- 第三步,在线服务时,来了一个
向量化召回不是单指某一个具体的算法,而是一个庞大的家族,比如:Item2Vec、Youtube的召回算法、Airbnb的召回算法、FM召回、微软的DSSM、双塔模型、百度的李生网络、阿里的EGES、Pinterest的PinSage、腾讯的GraphTR等。这些向量化召回算法,从召回方式上分,涵盖了U21、I21、U2U21三大类;从算法实现上分,有的来自"前DNN"时代,有的基于深度学习,还有的基于图算法;从优化目标上分,有的是按照多分类问题来求解,有的基于Learning-To-Rank(LTR)思路来优化。
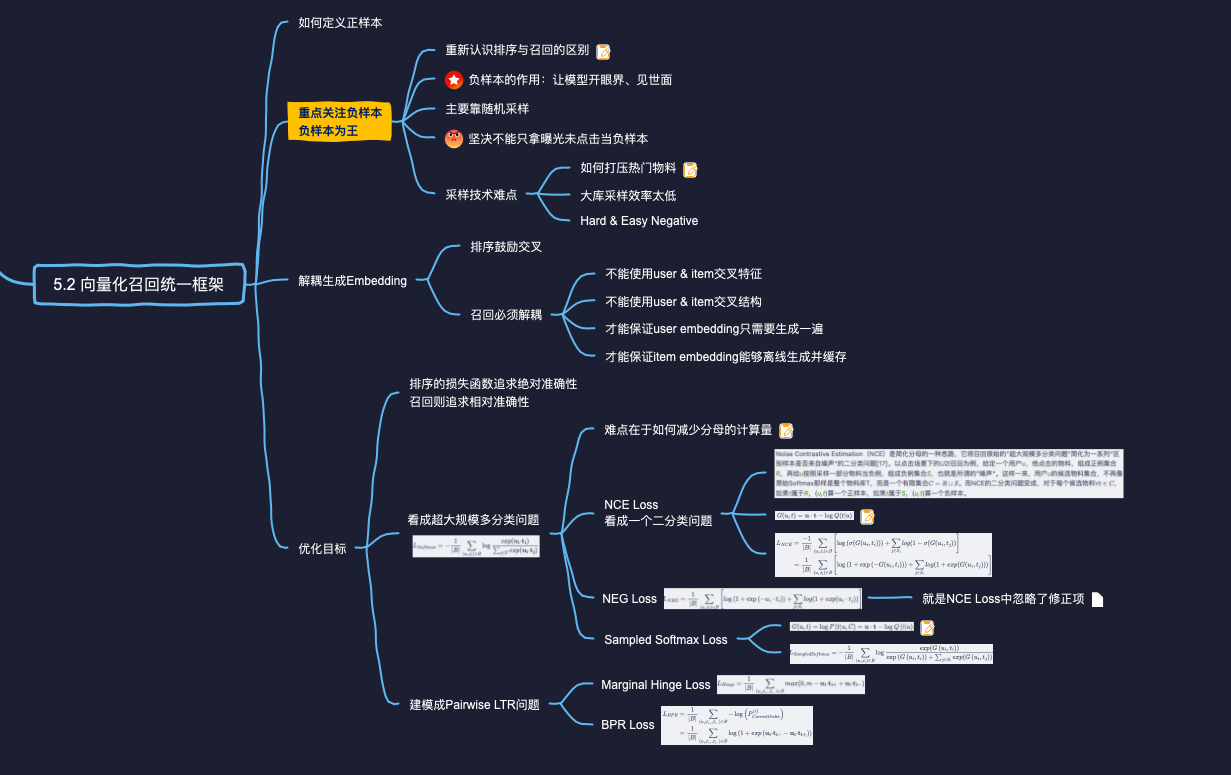
向量化召回算法,其实都可以用一套统一的建模框架所囊括。统一建模框架由4个维度构成:
- 如何定义正样本,即哪些
- 如何定义负样本,即哪些
- 如何将
- 如何定义优化目标,即如何制定损失函数;
# 如何定义向量化召回中的正样本?
正样本的定义,即哪些q和的向量表示应该相近,取决于不同的召回场景:
- I2I召回:q和t都是物料。比如我们认为同一个用户在同一个会话"(Session,彼此间隔时间较短的用户行为序列)交互过(e.g.,点击、观看、购买等)的两个物料,在向量空间是相近的。这体现的是,两个物料之间的"相似性";
- U2I召回:q是用户,t是物料。一个用户与其交互过的物料,在向量空间中,应该是相近的。这体现的是,用户与物料之间的"匹配性"。
- U2U召回:q和t都是用户。比如使用孪生网络,q是用户一半的交互历史,t是同一用户另一半交互历史,二者在向量空间应该是相近的,体现"同一性"。
# 为什么不能只拿"曝光未点击"做召回模型的负样本?
召回是将用户可能喜欢的item,和用户根本不感兴趣的海量item分离开来,他面临的数据环境相对于排序来说是鱼龙混杂的。机器学习的一条最最基本的原则铁律,就是"离线训练时的数据分布,应该与线上服务时的数据分布,保持一致”。
所以我们希望召回训练数据的正样本是user和item匹配度最高的那些样本,也即用户点击样本,负样本是user和item最不匹配的那些样本,但不能拿“曝光未点击”作为召回模型的负样本,这牵扯到推荐系统里常见的"样本选择偏差"(Sample Selection Bias,SSB)问题,因为我们从线上日志获得的训练样本,已经是上一版本的召回、粗排、精排替用户筛选过的,即已经是对用户“匹配度较高”的样本了,即推荐系统以为用户会喜欢他们,但用户的行为又表明的对他的嫌弃。拿这样的样本训练出来的模型做召回,并不能与线上环境的数据分布保持一致。也就是说曝光未点击既不能成为合格的正样本,也不能成为合格的负样本。
因此,为了让模型"开眼界、见世面",喂给召回模型的负样本,主要依靠随机采样生成。特别是在U21召回场景中,坚决不能(只)拿"曝光未点击"当负样本。
召回模型的负样本全部由"曝光未点击"组成是绝对不行的。但是,"以随机负采样为主,以曝光未点击为辅"的混合方案,能否行得通?业界尚无定论。以业界的经验,都认为"曝光未点击"样本就是"鸡肋",于召回模型无益。而在另外一些实践中,认为"曝光未点击"是Hard Negative,能够提升模型对细节的分辨能力。在随机负采样之外,加入"曝光未点击"能否提升召回性能?可以具体在工作场景中亲自实践一下。
如果说排序是特征的艺术,那么召回就是样本的艺术,特别是负样本的艺术。做召回,"负样本为王”,负样本的选择对于算法成败是决定性的:选对了,你就稳过及格线;选错了,之后的特征工程、模型设计、推理优化都是南辕北辙,无本之木,平添无用功罢了。
# 随机负采样在实践中有哪些讲究?
只通过随机采样获得负样本,可能导致模型的精度不足。举个例子,假如你要训练一个“相似图片召回"算法。当q是一只狗时,正例+是另外一只狗。负例t,在所有动物图片中随机采样得到,大概率是抽到猫、大象、乌鸦、海豚等图片。这些随机负样本,能够让模型"大开眼界”,从而快速"去伪存真"。但是猫、大象、乌鸦、海豚等随机负例,都与正例(另一只狗)相差太大,使模型觉得只要能分辨粗粒度差异就足够了,没有动力去注意细节。这些负样本被称为Easy Negative。
因此,我们要为"q=狗,t+=另一只狗"配备一些狼、狐狸的图片做负例。这些负例称为Hard Negative,它们与正例还有几分相似,能给模型增加难度,迫使其关注细节。
需要特别强调的是,Hard negative:并非要替代随机采样得到的Easy Negative,而是作为Easy Negative的补充。在数量上,负样本还是应该以Easy Negative为主,Facebook的经验A是将比例维持在Easy:Hard=100:1。毕竟线上召回时,候选集中绝大多数的物料都是与用户八杆子打不着的,保证Easy Negative的数量优势,才能Hold住召回模型的及格线。
# 为什么排序鼓励交叉?而召回要求解耦呢?
排序鼓励交叉:
- 特征上,排序除了单独使用用户和物料特征,最重要还使用了大量的交叉统计特征,比如"用户标签与物料标签的重合度”。这类交叉统计特征是衡量"用户物料匹配程度"的最强信号,但是它们无法离线事先计算好,服务于所有用户请求。
- 模型上,排序一般将用户特征、物料特征、交叉统计特征拼接成一个大向量,喂入DNN,让三类特征层层交叉。从第一个全链接层(Fully Connection,FC)之后,你就已经无法分辨,它输出的向量中,哪几位属于用户信息?哪几位属于物料信息?
排序之所以允许、鼓励交叉,还是因为它的候选集比较小,最多不过一两千个。
召回要求解耦:
换成召回那样,要面对十万、百万级别的海量候选物料,如果让每个用户与每个候选物料都计算交叉统计特征,都过一遍DNN那样的复杂运算,是无论如何也无法满足线上的实时性要求的。
所以,召回必须解耦、隔离用户信息与物料信息:
- 特征上,召回无法使用,用户物料之间的交叉统计特征(比如:用户标签与物料标签之间的重合度)。
- 模型上,召回不能将用户特征、物料特征一古脑扔进DNN,两者必须独立发展。用户子模型,只利用用户特征,生成用户向量
,
这样解耦的目的
- 离线时,不必知道是哪个用户发出请求,提前计算好生成百万、千万量级的物料向量(
, - 在线时,独立生成用户向量(
,
# 召回和精排在定义损失函数上有什么不同?
如何定义损失函数,召回与精排有很大不同。精排追求的预测值的"绝对准确性",它使用BinaryCross--Entropy Loss,力图将每条样本的CTR/CVR预测得越准越好。这是因为:
- 精排的候选集小,而且每个负样本都来自用户的真实反馈,因此精排有条件把每个负样本的CTR/CVR都预测准确。
- 精排打分的准确性,是下游任务(比如广告计费、打散重排等)成败的关键。因此,如果精排打分只能保证“将用户喜欢的排在前面"的"相对准确性",那是远远不够的。
而召回的优化目标、损失函数主要考虑的是排序的"相对准确性"
- 召回的候选集非常庞大,而且只有正样本来自用户真实反馈,而负样本往往都未曾向用户曝光过,所以召回没条件对负样本要求预测值绝对准确。召回常用的一类损失函数是多分类的Softmax Loss,只要求把正样本的概率预测得越高越好。
- 召回的作用是筛选候选集,只要能把用户喜欢的排在前面就好。因此,召回中另一类常用的损失函数遵循Learning-To-Rank(LTR)思想,不求预估值的绝对准确,只追求排序的相对准确性。
# NCE Loss的基本思想与计算公式
# NEG Loss的基本思想与计算公式?它与NCE Loss是什么关系?
# Marginal Hinge Loss的基本思想与计算公式
# BPR Loss的基本思想与计算公式
# Sampled Softmax的基本思想与计算公式
# Sampled Softmax中温度修正的作用?调高温度什么影响?调低温度有什么影响?
双塔模型损失函数中的温度调整系数
温度
- 如果
- 如果
# 采样修正的Q(t)应该如何设置?
公式中的
如果我们使用"混合负采样",损失函数如下所示。
- 与上题中唯一的不同之处就是在生成负样本时,引入额外的负样本B,B代表之前生成的物料向量的缓存
因为现在负采样来自两种采样策略,因此