# 传统的分布式计算存在什么不足?
其实推荐系统对海量数据并不陌生,我们有Hadoop/Spark这样的大数据工具对付它们。所以很直觉的想法就是,能不能也拿Hadoop/Spark来分布式地训练模型?想想也很简单:
- 将训练数据分散到所有Slave节点。
- Master节点将模型的最新参数广播到所有Slave节点。
- 每个Slave节点收到最新的参数后,用本地训练数据,先前代再回代,计算出梯度并上传至Master。
- Master节点收集齐所有Slave节点发来的梯度后,平均之,再用平均后的梯度更新模型参数。
- 回到步骤1,开始下一轮训练。
看上去似乎行得通。但是该方案忽略了推荐系统中数据的第二个特点,"高维稀疏的特征空间",给以上方案造成了两个困难:
- 推荐系统的特征动辄上亿、上十亿,每个特征的Embedding:是16位、32位甚至更长,这么大的参数量是一台Master所容纳不下的。
- 每轮训练中,Master节点都要将这么大的参数量广播到各Slave节点,每个Slave还要将相同大小的梯度回传,占据的带宽、造成的时延都是不敢想像的,绝对达不到在线实时训练的需求。
# 简述Parameter Server:是如何应对推荐系统“高维稀疏"的数据环境的?
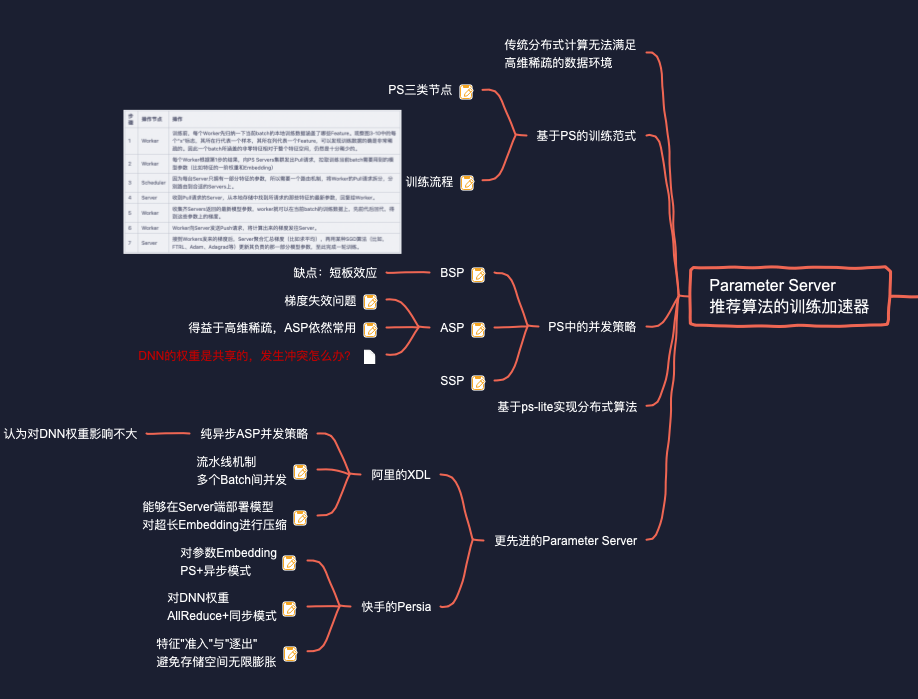
为了解决推荐系统中大规模分布式训练的难题,经典论文《Scaling Distributed Machine Learning with the Parameter Server》)提出了Parameter Server架构I6]。简单来说,Parameter Server就是一个分布式的KV数据库,两点设计使它能够克服Master/Slave架构应用于大规模分布式训练时的困难:
- 模型参数不再集中存储于单一的Master节点,而是由一群PS server节点共同存储、读写,从而突破了单台机器的资源限制,也避免了"单点失效"问题。
- 得益于推荐系统的特征是超级特征的特点,一个batch的训练数据所包含的非零特征的数目是极其有限的。因此,我们在训练每个batch时,没必要将整个模型的所有参数(i.e,上亿个Embedding)在集群内部传来传去,而只需要传递当前batch所涵盖的有限几个非零特征的参数就可以了,从而能够大大节省带宽与传输时间。
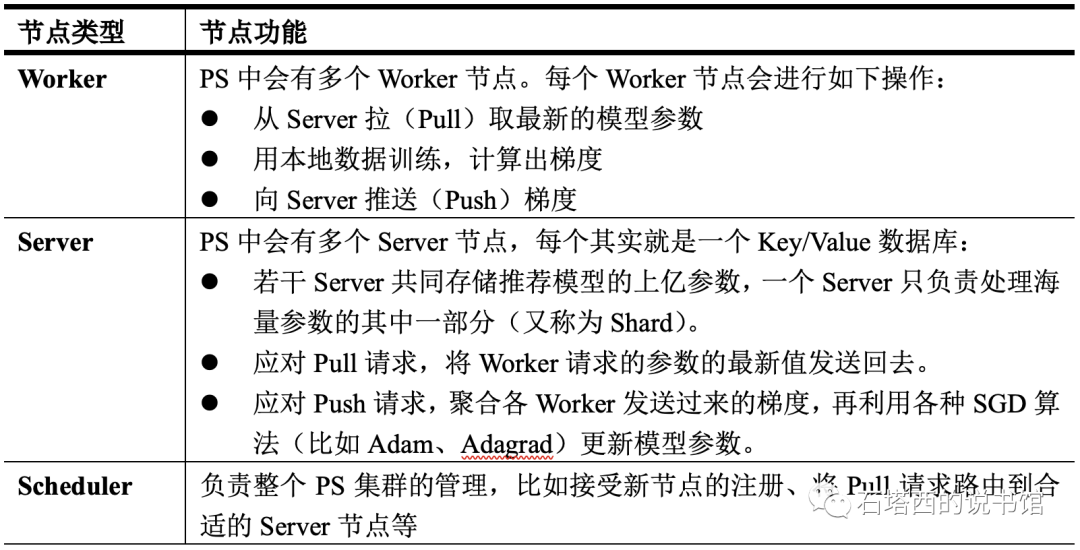
结构上一个Parameter Server主要由三大类节点组成,如图所示,各类节点的功能如表所示。
 基于Parameter Server的训练流程如下图所示,每个步骤的具体描述见下表。
基于Parameter Server的训练流程如下图所示,每个步骤的具体描述见下表。
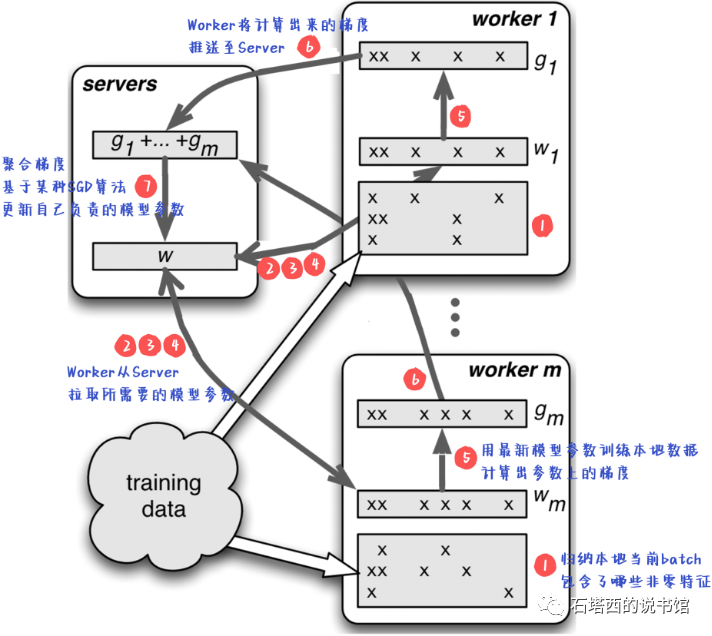

总结下来,Parameter Serveri训练模式是Data Parallelism(数据并行)与Model Parallelism(模型并行)的这两种分布式计算范式的结合体:
- Data Parallelism:数据并行很好理解,海量的训练数据分散在各个节点上,每个节点只训练本地的一部分数据,多机并行计算加快了训练速度。
- Model Parallelism:推荐系统中的特征动辄上亿,每个Embedding.又包含多个浮点数,这么大的参数量是单机无法承载的,必然分布在一个集群中。接下来,我们也会讲到,由于推荐系统中特征高度稀疏的性质,一轮迭代中,不同Worker节点不太会在同一个特征的参数上产生竞争,因此多个Worker节点相对解耦,天然适合Model Parallelism。
# 简述PS同步并发(BSP)的步骤,有什么优缺点?
同步并发策略(Bulk Synchronous Parallel,,BSP)下,顺序执行以下四步,如图所示:
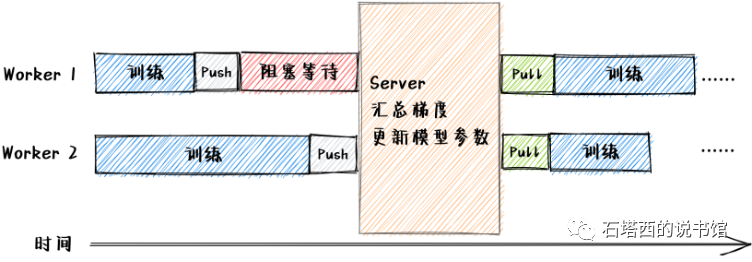
- 各Worker完成自己的本轮计算,将梯度汇报给Server,然后阻塞等待。
- Server在收集齐所有Worker上报的梯度后,聚合梯度,用SGD算法更新自己负责的那部分模型参数。
- Server通知各Worker解除阻塞。
- Worker接到解除阻塞的通知,从Server拉取更新过的模型参数,开始下一轮训练。
这种模式的优点是,多个Worker节点更新Server上的参数时不会发生冲突,所以分布式训练的效果赞同于单机训练的效果。缺点是,一轮迭代中,速度快的节点要停下来等待速度慢的节点,从而形成了"短板效应”,一个慢节点就能拖累整个集群的计算速度。
# 什么是PS异步并发(ASP)中的“梯度失效"问题?即使如此,为什么在推荐系统中仍然常用?
在异步并发策略(Asynchronous Parallel,ASP)下,每台Vorker在推送自己的梯度至Server后,不用等待其他Vorker,就可以开始训练下一个patch的数据。由于无须同步,不存在"短板效应",ASP具有明显的速度优势。
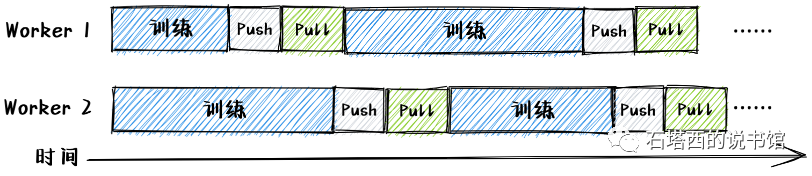 但是由于缺乏同步控制,ASP可能发生"梯度失效"(Stale Gradient)的问题,从而影响收敛速度。举一个极
度简化的例子:
但是由于缺乏同步控制,ASP可能发生"梯度失效"(Stale Gradient)的问题,从而影响收敛速度。举一个极
度简化的例子:
- 当前Server端上模型参数的版本是
- Worker 1的速度比较快,很快训练完本地数据并向Server上报梯度
- Server收到
- 此时Worker 2才完成计算并向Server上报了自己的梯度
- Server收到
但是在实践中,这个"梯度失效"问题并没有那么严重。得益于推荐系统中的特征超级稀疏的特点,在一轮迭代中,各个Worker节点的局部训练数据所包含的非零特征,相互重叠得并不严重。多个Vorker节点同时更新同一个特征的参数(i.e.,一阶权重或Embedding)的可能性非常小,所以Servert端的冲突也就没有那么频繁和严重,ASP模式在推荐系统中依然比较常用的。 细心的读者可能会有疑问,在一轮训练中,特征是稀疏的,两个Woker不太可能同时更新同一个特征的参数,使用ASP也较少发生冲突,但是DNN中各层的权重是所有Worker都要更新的吧,使用ASP导致了冲突怎么办?这是一个非常好的问题,也是现代Parameter Server改进的方向之一。
# 什么是半同步半异步?
半同步半异步(Staleness Synchronous Parallel,SSP)是BSP与ASP的折衷方案。SSP允许各Worker节点在一定迭代轮数之内保持异步。如果发现最快Worker节点与最慢Worker节点的迭代步数之差已经超过了允许的最大值,所有Worker都要停下来进行一次参数同步,如图所示。SSP希望通过折衷,实现"计算效率"与"收敛精度"之间的平衡。
