# 共享Embedding有哪些好处?
所谓共享Embedding,是指同一套Embedding要喂入模型的多个地方,发挥多个作用。共享Embedding的好 处有二:
- 一来,能够缓解由于特征稀疏、数据不足所导致的训练不充分。
- 二来,Embedding矩阵一般都很大,复用能够节省存储空间。
比如,模型要用到"近7天安装的APP"、"近7天启动过的APP"、"近7天卸载的APP"这三个Fild,而每个具体的APP是一个Feature,要映射成Embedding向量。如果三个Field不共享Embedding:
- "装启卸"三个Field都使用独立的Embedding矩阵来将APP映射成稠密向量,整个模型需要优化的参数变量是共享模型的3倍,需要更多的训练数据,否则容易过拟合。
- 每个Field的稀疏程度是不一样的,同一个APP,在"启动列表"中出现得更频繁,其Embedding向量就有更多的训练机会。而在"卸载列表"中较少出现,其Embedding向量得不到足够训练,恐怕最后与随机初始化无异。如果担心以上两点,那么我们可以让"装启卸"这三个Field共享一个Embedding矩阵。
# 既然共享Embedding有很多好处,那为什么有的特征要独占Embedding?
共享Embedding:最大的优点,就是缓解因为数据不足而导致的稀疏特征训练不充分的问题。但是各互联网大厂最不缺的就是数据,这时共享Embedding的缺陷就暴露出来,即不同目标在训练同一套Embedding时可能相互干扰。 比如APP的安装、启动、卸载,对于要学习的APP Embedding有着不同的要求。理想情况下,"安装"与"启动"两个Field要求APP Embedding能够反映出APP为什么能够招人喜欢,而"卸载"这个Field要能够反映出APP为什么招人烦。举个例子,有两款音乐APP,它们都因为曲库丰富被人所喜欢,"安装"与"启动"这两个Field要求这两个音乐APP的Embeddingi距离相近;但是这两个APP的缺点不同,一个是因为收费高,另一个是因为广告频繁,因此"卸载"Field要求这两个音乐APP的Embedding相距远一些。显然,用一套APP Embedding很难满足以上两方面的需求,所以大厂一般选择让"装/启/卸"三个Field-各自拥有独立的Embedding矩阵。 同理,用户有着不同类型的行为历史,比如点击历史、购买历史、收藏历史、点赞历史、,各种历史行为序列都是由一堆ltem ID组成。各种类型的动作对Item ID Embedding所表达的语义有着不同的要求,为了避免相互干扰,同一个物料在不同的行为序列中可以使用不同的ltem ID Embedding。而且参与刻画用户行为历史的ltem ID Embedding,与被用于物料特征的ltem ID Embedding,也彼此隔离,互不共享。 更有甚者,大厂的推荐系统都是多目标的,比如要同时优化点击率、购买率、转发率、等多个目标。有一些重要特征,在参与不同目标的建模时,也要使用不同的Embedding。
# FFM针对FM的改进在哪里?
另一个独占Embedding的重要应用场景,发生在特征交叉的时候。比如在Factorization Machine(FM)中每个Feature与不同Feature交叉时,使用的是同一个Embedding,如下所示:
公式说明,无论特征与哪个特征交叉,FM都是用相同u:来生成交叉特征的系数,即Embedding是共享的。这可能存在互相干扰的问题,比如模型调整以便把学习好,但是却可能对另一对特征组合的系数造成负责影响。
为了解决这一问题,业界提出了FM的改进版本Fieldaware Factorization Machine(FFM),在Kaggle比赛中取得了更好的效果。其核心思想是,每个特征在与不同特征交叉时,根据对方特征所属的Field要使用不同的Embedding。
FFM的一大缺点在参数爆炸。原来FM中,每个Feature只有一个Embedding,如果系统中有n个feature,每个Feature Embedding的长度为k,Embedding部分的参数总量是
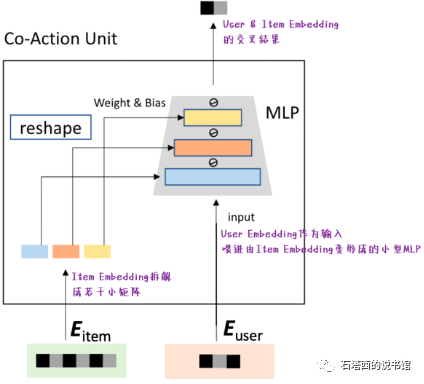
# 简述阿里Co-Action Network的基本思想?
2021年,阿里妈妈提出了Co-Action Network(CAN),在"独占Embedding"这条技术路线上又迈进了一大步。在笔者看来,CAN的目标有两个:
- 既想像FFM那样,让每个特征在与其他不同特征交叉时,使用完全不同的Embedding。
- 又不想像FFM那样引入那么多参数,导致参数空间爆炸,增加训练的难度。
为了兼得以上两个目标,CAN提出如图所示的网络结构进行特征交叉。
,
CAN的优势在于:
- 根据公式,
- 与此同时,CAN并没有像FFM那样为每对特征交叉都引入独立的参数。参数空间没有爆炸,计算压力、存储压力、训练不充分等问题都得以缓解。