# 请简述A/B实验的思路与步骤,它存在什么优缺点?
A/B实验(AB Testing)是推荐系统中最重要、最流行、最常见的线上评估方式。AVB实验的思路与步骤,说起来很
简单:
- 把用户流量随机划分为"控制组"(Control Group,又称对照组)与"实验组”(Experiment Group)。
- Control Group走老模型,Experiment Group走新模型。模型差异是两组流量的唯一差异,其他影响因素(比如用户分布、物料分布、实验模型上下游的其他模型与策略)必须完全相同。这也就是AB实验最最重要的"同分布"原则。
- 上线实验一段时间,让两组流量积累起足够多的用户反馈。
- 通过收集到的用户反馈,分别统计出两组流量上的关键业务指标。
- 通过数据分析,如果发现Experiment Group上的关键业务指标"显著"优于Control Group,我们就有充分理由相信新模型优于老模型,可以考虑由新模型替换老模型。
AB实验的优点:
- 作为一种数据驱动的决策方式,AVB实验更加客观,避免了"拍脑袋"那样的主观决策。
- 随机划分流量,(尽力)使除要实验的因素之外的其他外部因素,在两组流量上保持一致,AB实验得出的结论比较公平可靠。
AB实验的缺点:
- 一套完整的AB实验系统,包括流量划分、数据记录、数据分析、图表展示、实验管理等众多功能模块,功能复杂,实现难度高。小团队没有时间与能力从头开发,可以采购市场上比较成熟的AB实验平台。
- 为了收集到足够多的样本使实验结果更加置信,AVB实验需要进行足够长的时间,时间成本比较高。更何况,用户行为往往呈现周期性(比如周末的用户活跃度大增),AB实验至少要覆盖一个完整的周期,实验一周是最起码的要求,实验更长时间也不鲜见。每次等待实验结果的过程,对算法工程师来说,都是一段兴奋与焦虑并存的难熬时光。AB实验虽然讲起来简单直观,但实践起来坑也不少。有可能我们不小心在划分流量时引入了偏差,使实验结果有失公平;有可能分析结果时违背了一些统计原则,基于正确的数据却得出了错误的结论。所以要将AB实验做好做正确,就需要我们具备扎实的理论基础和缜密的心思手段,并且在实践中积累经验。
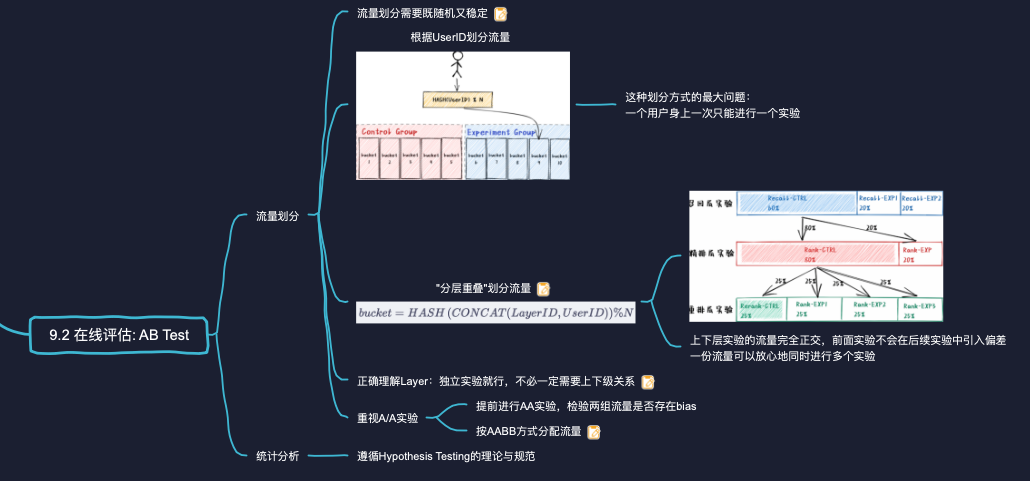
# AB Test中应该如何划分流量?简述A/B实验的流量"分层重叠"的划分方式。
"分层重叠"的流量划分方式是Google在文献3]中提出的,其思想是:
- 假设一共要进行N个实验,就将流量划分为N层,每个实验独占一层。
- 同一层实验的各个实验组,其流量是互斥的。一个用户的请求,在一个实验中,只会命中一个实验组。
- 不同层的实验,其流量是重叠的。一个用户的请求,在不同实验中,会命中多个实验组。
"分层重叠"实现起来也很简单,如下所示:
- 在Hash时引入了LayerlD。LayerID是一层流量的唯一标识。因为每个实验独占一层流量,所以LayD也可以看成是一个实验的唯一标识,比如独一无二的实验名。用户请求每进入一个新实验,因为LayerlD发生变化,就相当于用户流量被重新打散一次。
- CONCAT代表拼接两个字符串
采用"分层重叠"的流量划分方式,上下层实验的流量完全正交,用户流量在前面几层实验中经历的不同对待,并不会在后续实验中引入偏差(bas)。所以,一个用户身上可以放心地同时进行多个实验流量利用效率大为提高,解决了推荐系统中众多要进行的实验与有限流量之间的矛盾。
# 为什么要重视A/A实验?你在做AB Test时,一般会有哪些注意事项?
所谓A/A实验,就是在Control Group和Experiment Group采用完全相同的配置。一个值得推荐的习惯就是在正式的A/B实验之前,先进行一段时间的A/A实验,检验要用于实验的两组流量是否存在偏差(bias)。
- 如果A/A实验的结果表明,两组流量在关键业务指标上的差异非常小,就说明两组流量没有偏差。我们可以放心地将新模型、新策略应用于Experiment Group上,开始正式的A/B实验。
- 否则,相同条件下两组流量的表现还存在明显差异,那我们就必须推迟A/B实验,先解决A/A差异的问题。一个比较大的可能性,这个差异属于正常波动。比如,我们判断A/A实验差异"明显"的标准是看这两组流量的指标之差,超出了95%或99%的置信区间,但毕竟还剩下1%~5%的可能性允许A/A差异超出这个置信范围,这个概率可比中彩票大多了。为了减少波动性,我们只需要增加两个组的流量份额。如果增加流量后,A/A实验差异依旧明显,就需要检查我们的代码、配置是否有bug了。
A/A实验除了开在A/B实验之前,也可以与A/B实验同步进行。比如,在一个实验按AABB的方式分配流量:
- A1和A2,使用相同配置的老模型。
- B1和B2,使用相同配置的新模型。
这样,我们能够在考察新老模型的差异的同时,观察两个模型的波动性。我们乐于看到的结果当然是,无论B1还是B2,其业务指标都要显著优于A1或A2。否则,就说明模型面对不同流量的表现非常不稳定,不适宜推广至全体流量。
# 请简述检验两组流量的指标均值是否相等这一假设检验的过程。用通俗语言解释一下什么是p-value?
以推荐系统中最常用的"检验两组流量的指标均值是否相等"为例,假设检验需要我们先建立两个假设:
值。
然后,我们让Control Group走老模型,让Experiment Group走新模型,开始AB实验。一段时间过后,我们收集到一批样本:
- Control Group下收集到
- Experiment Group下收集到
接下来,我们计算在
通过查表或调用程序,我们就能得到在标准正态分布下大于
最后,拿p-value与我们事先定义好的显著性水平(Significance Level))
- 如果
- 否则,说明在
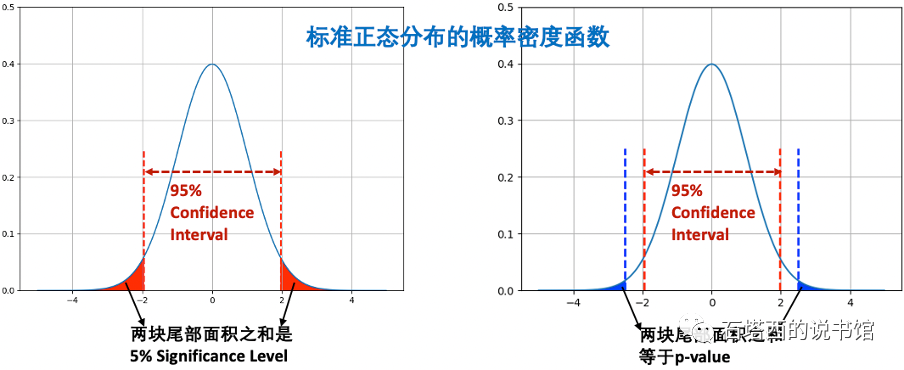
# 请简述一类错误和二类错误的概念。(解释一下什么是Type I Error, Type II Error, Power?)
除了p-value,在阅读A/B实验的分析报告中,还经常碰到两个概念,一类错误(Type I Error))和二类错误(Type ll Error)),如下所示。

从图中可以看到,Confidence Interval与Significance Interval的边界向左移,发生Type I Error的概率a增加,发生Type ll Error的概率减小;反之,边界向右移,
# 分析AB实验的结果,还有需要注意的点吗
分析A/B实验的结果,还有两点需要注意: