
# 传统召回算法在主流的深度学习算法(如双塔、图卷积)之下为什么很有必要?优势是什么?
传统召回算法主要基于规则和统计,较少训练模型,尽管不如后来的基于深度学习、图卷积的召回算法亮眼。但在某些场景下,仍然有用武之地。
原因之一是,复杂的算法,虽然效果更好,但是训练、部署都需要消耗更多的资源,训练时也需要更多的数据。而这些条件,都是一些初创团队所不具备的。这时,传统召回算法,就体现出训练方便、易于部署、易于调试等优势。甚至在一些小项目中,整个推荐算法不需要排序,就只有一个召回模块就足够了。
第二个原因在于,即使是大厂的推荐系统,也并非是完全自动化、智能化的。推荐工程师也经常需要配合其他业务团队完成一些临时性、运营性的需求。比如,近期业务团队的目标是提升文章的转发分享率。如果要让你的DNN模型配合这个需求,你可以添加一些与转发分享相关的特征,还可以提升"转发"目标在最终损失中的权重。但是,众所周知,DNN是个黑盒,改进模型的效果未必是立竿见影的。
这时,传统召回就显现出巨大的优势。比如,要想提升转发率,
- 你可以新增一路叫"高转发"的召回。先离线统计出每个文章类别下转发率最高的前若干篇文章,存进倒排索引;
- 线上来了一个用户请求,根据该用户喜欢的文章分类,找到相应的索引,返回其中高转发的文章;
- 再做一些策略上的调整,使被"高转发"召回的文章,能够在最终返回给用户的结果集中出现得尽量多一些。
由此可以看出,传统召回算法简单直接,使我们能够更敏捷地应对业务需求,在现代推荐系统中仍然有一席用武之地。
# 如何基于物料的属性构建倒排索引召回?
离线时将具备相同属性的物料集合起来,每个集合内部按照后验消费指标(比如CTR、WCTR)降序排列。比如下图中,所有带有"坦克"标签的文章组成集合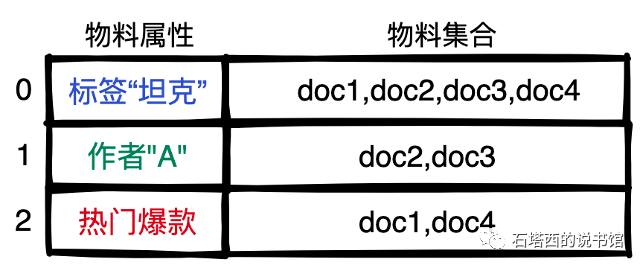
线上来了一个用户请求,提取用户喜欢的标签、关注的作者等信息,再据此检索倒排索引,把对应的物料集合作为召回结果返回。
# 基于统计的协同过滤算法是怎么做的?优势是什么?
协同过滤算法分为两种:
- 基于用户的协同过滤(User CF):给用户A找到与他有相似爱好的用户B,把B喜欢的东西推荐给A。
- 基于物料的协同过滤(Item CF):用户A喜欢物料C,找到与C相似的其他物料D,把D推荐给A。
传统的协同过滤,无需训练模型,是完全基于统计的。以ItemCF为例:
首先,定义用户反馈矩阵
再计算
从以上流程,可以看出Item CF的优势:
- 相比于庞大数量的用户,物料的数目更少而且稳定,因此
- 还是因为物料数目相对较少,ATA也不会很大。在利用
感兴趣的读者可以参考文献[Scalable similarity-based neighborhood methods with MapReduce],其中介绍了一个基于MapReduce实现Item CF的通用框架,支持用cosine、Pearson相关系统、Euclidean距离、Jaccard距离等多种方式计算相似度。
# 多路召回合并一般的做法是什么样的?有什么优势呢?
出于"冗余防错"和"互相补充"的目的,推荐系统中通常会有多路召回,这些召回各自的结果,需要合并进一个结果集,再传递给下游的粗排或精排模块。合并时,重复的召回结果只保留一份。如果合并后的结果集太大,超出下游粗精排的处理能力,需要截断。
第一种合并方法,如下列代码所示。这种方法,人为给各路召回指定了一个插入顺序。如果前面的召回把结果集插满了,后面召回的结果只能被丢弃。
def wrong_merge_recalls():
merged_results = {}
# recall_method:某一路的召回算法名
# recall_results:此路召回的结果集
for recall_method, recall_results in recall_results_list:
capacity = MAX_NUM_RECALLS - len(merged_results) # merged_results还剩余的额度
if capacity == 0:
#已经插满了,直接返回,后面的召回的结果被丢弃
return merged_results
# 当前召回能插入最终结果集的额度
quota = min(len(recall_results), capacity)
#把当前结果集中的top quota个物料,插入到最终结果集中
top_recall_results = recall_results[:quota]
merged_results.update(top_recall_results)
return merged_results
2
3
4
5
6
7
8
9
10
11
12
13
14
15
这种方式的缺点在于
- 人为规定的插入顺序太主观。如果排在前面的召回退化了,而排在后面的召回进步了,怎么办?
- 而且不同用户对不同召回的偏好不同,怎么会有一个死板、统一的标准?
所以正确的方式,应该如下列代码所示。
def correct_merge_recalls():
merged_results = {}
while True:
# recall_method:某一路的召回算法名
# recall_results: 此路召回的结果集
for recall_method, recall_results in recall_results_list:
if len(merged_results) == MAX_NUM_RECALLS:
return merged_results # 插满了,返回
if len(recall_results)> 0: #当前召回还有余量
#弹出当前召回认为的用户最喜欢的item,插入结果集
top_item = recall_results.pop()
merged_results.add(top_item)
2
3
4
5
6
7
8
9
10
11
12
- 各路召回的结果集,按照预估的用户喜欢程度降序排列,用户最可能喜欢的物料排在最前面。
- 每一轮合并,把所有召回都遍历一遍。每路召回,将各自结果集的第一名弹出,插入合并结果集。
重复以上合并过程若干轮,直到最终结果集被插满。
这种合并方式的优点在于,不必刻板地指定各路召回的插入顺序,也就不会出现顺序靠后的召回的结果被全部丢弃的情况,能够确保各路召回的精华肯定会被插入到合并结果集中,从而获得下游的处理机会。