# 传统的逻辑回归有哪些特点和缺陷?
LR(评分卡)模型的特点:
- LR的特点就是强于记忆,只要评分卡足够大(比如几千亿项),它能够记住历史上的发生过的所有模式(i.e,特征及其组合)
- 所有的模式,都依赖人工输入。所以在推荐模型的LR时代,特征工程既需要创意,同时也是一项体力活。
- LR本身并不能够发掘出新模式,它只负责评估各模式的重要性。这个重要性是通过大量的历史数据拟合得到的。
- LR不发掘新模式,反之它能够通过"正则"(Regularization),别除一些得分较低的罕见模式(比如<中国人,于谦在非洲吃的同款恩希玛>,既避免过拟合,又降低了评分卡的规模。
LR(评分卡)模型,强于记忆,但是弱于扩展。只有记忆功能,所以无法应对个性化小众需求。
# 如何在LR模型中增强特征的扩展性?
在训练LR模型的时候,每条样本除了将原来细粒度的概念<春节,中国人,饺子>和<感恩节,美国人,火鸡>作为特征,也将扩展后的<节日,和节日相关的食物>作为特征,一同喂入LR模型。这样训练后的"评分卡"不仅包含对<春节,中国人,饺子>和<感恩节,美国人,火鸡>的打分,也包含对粗粒度特征<节日,和节目相关的食物>的打分。而且因为<节日,和节日相关的食物>在训练数据中出现频繁,所以这一项必然在“评分卡”中占据一席之地,不会被正则机制过滤掉。 这样一来,当模型考虑是否应该在春节期间为一个中国顾客推荐火鸡时,虽然<春节,中国人,火鸡>这样的细粒度模式,因为太过小众,没能命中评分卡。但是扩展后的粗粒度模式<节日,和节日相关的食物>,却命中了评分卡,并获得一个中等分数,从而有可能获得曝光的机会。相比于原来被L1正则优化掉,”一些中国人喜欢开洋荤"的小众模式也终于有了出头之日。 这样看来,只要我们喂入算法的,不是细粒度的概念,而是粗粒度的特征向量,即便是LR这样强记忆的算法,也能够具备扩展能力。但是,上述方法依赖于人工拆解,也就是所谓的"特征工程",从而带来两方面的缺点:
- 工作量大,劳神费力。
- 比如饺子、火鸡这两个概念,还能不能从其他角度拆解,从而发现更多的相似性?这就要受到工程师的业务水平、理解能力、创意水平的制约。
# 为什么说Embedding提升了推荐算法的扩展性?
深度学习对于推荐算法的贡献与提升,其核心就在于Embedding。Embedding是一门自动将概念拆解为特征向量的技术,目标是提升推荐算法的扩展能力,从而能够自动挖掘那些低频、长尾、小众的模式,拥抱"个性化推荐"的"蓝海"。那么Embedding到底是如何提升扩展能力的?简单来说,Embedding将推荐算法从"精确匹配"转化为"模糊查找",从而让模型能够举一反三”。
比如在使用倒排索引的召回中,是无法给一个喜欢"科学"的用户,推出一篇带"科技"标签的文章的(如果不考虑近义词扩展的话),因为"科学"与"科技"是两个完全不同的词。但是经过Embedding,我们发现在向量空间中,表示"科学与"科技"的两个向量,并不是正交的,而是有很小的夹角。设想一个极其简化的场景用户就用"科学"向量来表示,文章用其标签的向量来表示。那么用"科学"向量在所有标签向量里做To-K近邻搜索,一篇带"科技"标签的文章就能够被检索出来,有机会呈现在用户眼前,从而破除之前因为只能精确配"科学"标签给用户造成的"信息茧房”。
# Embedding具体在操作上是进行的?
Embeddingi在操作起来还是非常简单的。假设我们有"音乐"、"影视"、"财经"、"游戏"、"军事"、"历史这6个文章类别,编号从0~5,我们想把每个类别映射成一个长度为4的稠密浮点数向量,整个过程如图所示。
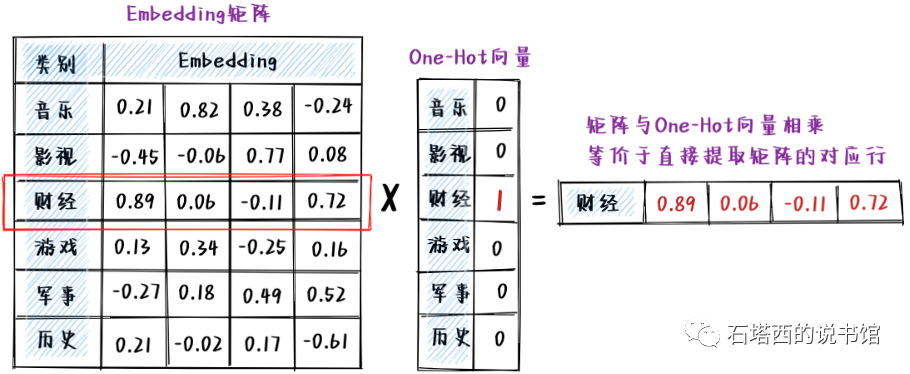
- 首先,我们定义一个6×4的矩阵,行数是要Embedding的特征的总数,列数是希望得到的向量的长度。
- 先随机初始化这个Embedding矩阵。矩阵的内容会随着主目标优化,训练结束时,矩阵内容会变成能表达"文章分类"语义的、有意义的数字。
- 以Embedding财经"这个类别为例,整个Embedding)过程从数学上相当于,一个稠密的Embedding矩阵,与只有"财经"所在的2号位置为1、其余位置全是0的One-Hot向量,相乘。得益于One-Hot向量的稀疏性,以上相乘过程又相当于,从Embedding矩阵直接提取"财经"所在的第2行(首行是0行)