# 对模型进行监控,可以从哪些方面入手?
解决方法就是加强对推荐模型的监控,通过观察模型黑盒的输入输出,使我们对模型状态有一个大致的了解,方便立刻发现问题和日后排查问题。
对模型的监控,包括但不限于如下几个方面:
- 输入样本的数量,还有其中各个目标的正负比例
- 各个特征对样本的覆盖情况
- 模型如果要访问外部服务(比如画像服务、获取预训练的Embedding等),这些外部服务是否正常更新?模型访问它们的时间延迟和失败率?
- 训练服务的吞吐量?在线训练的样本队列是否发生阻塞?
- 在线持续评估得到的模型的各方面指标
- 部署模型是否正常?
- 模型预估结果与用户真实反馈(比如预测CTR和线上真实CTR),以及二者之间的差距
- 召回结果中各路召回所占比例、最终展示给用户的结果中各路召回所占比例
监控时,不仅要看整体指标,还要细分。比如模型在不同人群(比如:新老用户、不同市场)、不同展示位置上的表现。
借助开源软件(如Grafana、Prometheus),我们可以存储、汇总这些监控指标,并将它们展示成各种报表、曲线,再组成监控看板。借助监控看板,我们发现、定位问题也变得相对容易。
举个例子,算法工程师的噩梦之一就是,之前好好的模型,线上指标(突然或缓慢)掉下来了。可以借助指标看板,
- 首先,发现"持续评估"曲线中,模型的离线指标也掉下来了,说明与线上环境无关,应该是模型本身出了问题。
- 接着,笔者发现输入样本中的CTR下降了,说明上游数据中正负样本比例发生了变化
于是,笔者询问了负责上游数据的同学,发现他们缩短了等待用户反馈的时间,导致一部分正样本由于未能等到用户反馈被当成负样本。就这样,问题被定位了,接下来修复就很容易了。
# 请说一说得到深度模型的特征重要性可以使用哪些方法?如何知道某个特征在你的模型中的特征重要性?
第一种方法叫Ablation Test,.其作法是
- 使用全部特征的训练数据集记为
- 在
- 在
- 我们拿
Ablation Test的缺点在于计算量太大。大型推荐模型,起码有几十个Field,要得到每个Field的重要性都需要重训一遍模型,而每次训练又都要涉及海量数据,费时费力。
第二种方法叫Permutation Test,它的作法是
- 首先在
- 对于特征
- 模型M在
- 我们拿
这个方法的优点在于,无需重新训练模型,因此在实践中应用得还比较普遍。其缺点在于,有些特征之间并非独立,而是相互关联,只打散其中一列,可能产生完全不符合常量的样本。比如推荐模型所使用的"物料分类"与"物料标签"就是强关联的,打散"标签"特征,可能会制造出分类是音乐、标签却是美食的问题物料。在这种特征分布与现实严重不符的样本上测试,得到的评估指标也就失去了意义,由此衍生出的特征重要性也要打上大大的问号。
第三种方法叫Top-Bottom Analysis,它的作法是:
- 训练得到模型M后,喂入
- 然后将
- 取头部N条样本与尾部N条样本,观察相同特征或特征组合在头部样本与尾部样本上的分布差异。分布差异越大,说明该特征对模型越重要。
第四种方法是"解释模型"法,要用到之前讲过的SENt和LHUC结构。给定一个样本,这类模型结构能够计算出其中每个特征的重要性。
事实上,同一个特征,甚至相同特征值,在不同样本中的作用也有显著不同。举例来说,UserID或ItemID在老用户、老物料的推荐中,发挥着重要使用,因为它俩是最个性化的特征。但对于新用户、新物料,这两个特征却毫无使用,甚至还可能帮倒忙,因为它俩的Embedding还没有训练好,基本上还是随机初始化的向量。
以上三种方法只能基于一整个数据集来衡量特征的重要性,UserlD/ItemID重要与否,取决于测试集中新用户、新老物料的比例,评估粒度太粗。而这正是"解释模型法"的优点,它能将评估范围缩小到样本粒度,赋予我们对单个badcase做针对性分析的能力。
当然要想获得特征的整体重要性也很简单,只需要汇总数据集中每个样本上的特征重要性,就能得到。类似的作法已经用于COLD,简化精排模型的输入特征以用于粗排,技术详情请见6.1.4节。
# 如何评价模型中每一个模块的作用?一个多层的DNN,你想压缩一下,如何找到"滥竽充数"那一层?
检查一个4层DNN中各个"全连接”(Fuly Connection,FC)层的使用。首先将N条测试样本喂入DNN,将各FC层的输出收集起来。
第一种是可视化方法。将每层输出的N个向量,利用t-SNE算法降维至2维空间,再画成散点图。其中每个点代表一条样本,红点代表点击样本,蓝点代表未点击样本。
- 第3层的输出(图9-10b)相比第2层的输出(图9-10(a),同一个Labelf的样本点分布得更加集中,正负样本间隔更加明显,说明第3层FC的确起到了提炼信息的作用。
- 第4层的输出(图9-10(c)相比于第3层的输出(图9-10b),正负样本的间隔反而更加模糊。这说明加入第4层FC帮了倒忙,反而损害了整个模型的区分能力,可以考虑删除之。

第二种方法与第一种类似,只不过更加量化,而无需依赖人工主观观察。这个方法中,用每层输出的N个向量拟合一个Logistic Regression(LR)模型,然后比较各层拟合出来的LR模型的性能。性能越高,说明该层输出中包含的信息量越大,也就说明该层的作用越大。注意,这里特意拟合LR而非更复杂的模型,就是为了让拟合模型的性能差异体现在输入向量的质量上,而不是拟合模型的功劳。
# 9.4 线上线下一致性

# 你碰到过“线下AUC涨了,线上AB指标没提升”的情况吗?怎么处理解决的?
首先先排查一下自己是否犯了一些简单但愚蠢"的错误,比如:
- 代码中是否出了bug?
- 配置A/B实验时是否出错?比如和别的实验起了冲突。
- 离线训练和评估所使用的数据集是不是太小了?
- 离线数据集是否包含了某个特殊事件(比如节日、促销等),从而削弱了其代表性。
如果你的确犯了"简单但愚蠢"的错误,你应该感觉到庆幸,毕竟省去了你继续排查下去的麻烦。因为接下来排查起来更麻烦,解决起来难度更大。
# 解释一下“特征穿越”现象,及如何解决?
模型要用到消费指标特征(比如用户在某个分类下的观看时长、物料在过去24小时的CTR等)。你将这些消费指标或计算指标所用的原始数据,存入数据库。线上预测与线下训练要用到这些特征时,都要访问数据库,获取指标的最新数值。同时这类特征都是动态的,需要有一个程序接收用户最新的动作反馈,实时更新数据库中的各类指标。整个结构如图所示。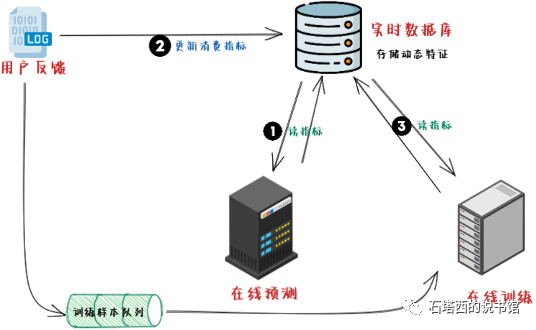
- 在"1时刻,预测程序访问数据库获取最新的消费指标。
- 接下来,预测程序将推荐结果返回给用户,用户做出反馈(比如点击、购买等)
- 在"2时刻",数据库接到了用户反馈,更新了数据库中的各项消费指标。
- 同时,"1时刻的用户请求+反馈"作为一条样本,插入"训练样本队列"”,等待训练模型。
- 过一会儿,到了"3时刻,在线训练程序拿到了"1时刻的请求+反馈”,开始训练。准备样本时,训练程序向数据库请求最新的消费指标,但问题是,此时数据库的消费指标已经在"2时刻"被更新过了。也就是说,训练程序要拟合"1时刻的用户反馈,但是用到的动态特征却来自"2时刻”。
模型在拟合用户反馈时,"未卜先知"地用到了反馈之后的信息,这种现象就叫"特征穿越”。这种行为相当于开了作弊器,离线评估的效果自然好。而到了线上预测时,失去了作弊器的加持,效果自然就被打回原型。
解决方法就是采用"特征快照"的方式生成样本,如图所示。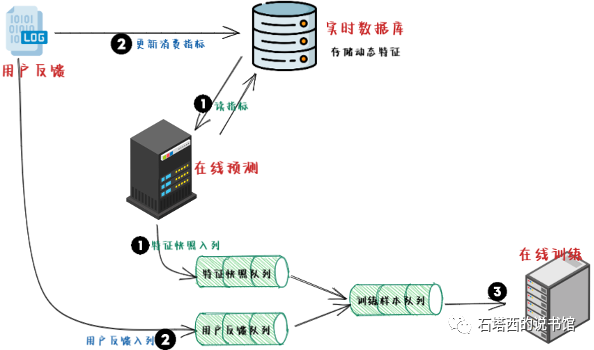
- 在"1时刻",预测程序向数据库请求最新的消费指标数值。
- 在将预测所需要的一切信息准备好后,一方面开始计算预估值,另一方面将所有信息打包成一个"快照"(Snapshot)),插入队列。"快照"意味着其中的信息都固定下来,不再受之后的用户行为而变化。
- "2时刻”,用户对预测结果的反馈,被插入"反馈队列。有程序将快照队列"与"反馈队列进行合并,将属于同一个请求的特征快照"与"用户反馈"拼接成一条完整样本,插入到"样本队列"中,等待训练。
- "3时刻”,训练程序从"样本队列"中提取样本,加以训练。此时,我们就能够保证训练程序见到的每一条样本,特征与Labeli都来自同一时刻,不会发生穿越。
"特征快照"方法也不是完美的,它最大的缺点在于,"快照"要将所有特征固定打包,"体积"可能小不了。以前还好,因为推荐系统中样本都是稀疏的,不会占用太大的空间。但是如果要在特征中使用一些预训练向量,因为这些预训练的向量都是稠密的,每条样本都打包一遍的话,会给内存、硬盘、带宽都带来极大的压力。此时,我们不得不要重走图1那样的老路,将预处理好的向量集中存储在数据库中,样本中只存储向量在数据库中的索引,训练时再访问数据库获取向量内容。不过需要特别注意的是:
- 图1的方法,只适用于根据内容(比如封面图片、文章内容)预训练的向量,因为这些向量基本不会变化,预测时与训练时请求,都会得到相同向量,没有穿越问题。
- 而对于根据用户行为预训练的向量,比如在精排的预测和训练阶段,都访问粗排双塔以获得的最新的用户向量、物料向量当特征,图1的方法肯定会引入穿越问题,因此不推荐使用。
# 你碰到过“老汤模型”带来的麻烦吗?如何解决?
线下评估时,为了保证公平,新老模型需要有相同或相近的初始状态(比如参数都是随机初始化的),但是这一条在线上实验中是做不到的。线上的老模型已经被在线持续更新了几个月,犹如一锅被炖煮了许久,而且还在被不停加料的老汤。"老汤模型"中的参数见多识广,久经考验,非初出茅庐的新模型所能比拟。比如在线预测时,某个特征(比如UserID)是新模型从未见过的,新模型只能用全零向量来代替它的Embedding,但是相同特征对老模型却算是"老熟人"了,老模型能够拿出充分训练过的向量作为该特征的Embedding,哪个效果更好,不言而喻。也就是说,新模型虽然能力强,但是经验却远不及老模型丰富,线上实验打不过老模型也在情理之中。
为了应对这一问题,新模型在上线前,必须拿历史数据回溯训练。但是为了赶得上老汤模型,回溯的时间也短不得,耗时长,效率低。为了提升回溯效率,我们让新模型从老模型参数的基础上热启训练,使新模型只需要回溯较短时间,就能追得上老模型。这就好比,新模型单靠自己从头学起,怎么也要花上个三年五载才能学出个模样。老模型觉得胜之不武,将自己多年的功力直接"传"给新模型,让新模型的功力立刻就能与自己不相上下。然后二者才开始公平比试,看谁能够更好地发挥这份功力。
热启训练如图所示。对于Embedding,新模型将老模型所有Embedding都拷贝过来作为初值。新老模型中共用的那部分特征将在老模型Embedding的基础上继续更新,只有新引入的Embedding才需要随机初始化。某个特征,在新模型中定义的长度是
最简单的情况就是
如果
如果
对网络结构的参数,处理方法与Embedding类似。对于新老模型复用的模块,新模型拿老模型相同模块的权重作为初值。如果出现尺寸不匹配的地方,也需要裁剪和补齐。比如中,新模型第1层FC的权重大部分都继承自老模型,此外还需要补上一块随机初始化的部分。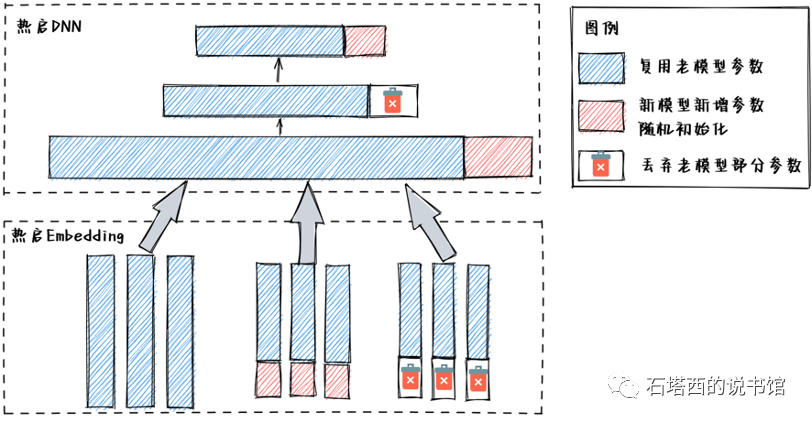
热启训练给新老模型提供了一个相对公平的起点,但是缺点也不少。
- 非常麻烦。新老模型之间的映射关系,没有规律可循,每次从老模型提取参数、剪裁、补齐、重填至新模型,都需要重新编写脚本与配置,费时费力还容易出错。
- 束缚了算法工程师的手脚,使我们不愿意对模型做大幅修改,只愿意小修小补。因为改动的地方越多,热启迁移也就越繁琐。而且改动多了,很多模块的映射关系也就不复存在,压根无法迁移。
- 缺乏理论保证。很多问题,比如在尺寸不匹配时,截断或补齐,究竟要发生在头部还是尾部?老模型已经训练好的参数当然是继续训川练的优秀初值,但是一个好初值搭配上一段随机初始化的向量,仍然是一个好初值吗?…,尚没有明确答案。大家在实践中都是凭自己的经验来操作的,缺乏扎实的理论支撑。
# 新模型小流量上线后,我收集了一批线上数据D做测试样本,让新老模型都在D上预测并计算GAUC,我的作法有什么问题?正确方式应该怎么做?
经常被大家忽视的一个问题就是,我们的离线评估方法本来就是"有偏"的(biased),存在"冰山现象",就拿精排来说,无论训练还是评估,我们都拿点击做正样本,曝光未点击做负样本。所谓离线评估效果好,只不过是说新模型在曝光样本上,也就是老版推荐系统筛选出来的那部分优质物料上,表现得比老模型要好。换句话说,新模型在露出海面的那一小部分冰山尖上表现出色。但我们并不能就此就得出"新模型优于老模型"的结论,因为毕竟新模型上线后要面对的是整座冰山,而非只有山尖。
对于老模型下未曝光的样本,相当于掩藏在水面下的大部分冰山,新模型从未见过,在它们身上的表现完全是个未知数。相同条件的在线预测,新模型可能会将一些本来被老模型打压、没有曝光机会的物料提升到前面,从而有机会向用户曝光。对于这部分物料,新模型既未训川练过,也未测试过,对用户的反映完全靠"猜”。万一猜错了,新模型的效果打不过老模型,自然也就毫不奇怪了,"愿赌服输"嘛。
本来以上缺陷也不算什么,毕竟新模型也会在线学习(Online Learning),持续更新。如果新模型猜错了,用户的负反馈会使它得到教训,从而完善自己,避免下次再犯同样的错误。但不幸的是,新模型刚上线时,都只占小流量,由新模型产生的样本是极其有限的。喂给新模型在线学习的,主要还是老模型产生的样本。换句话说,新模型在线学习的主要还是别人的成败得失,对自己的错误没有给予足够的重视,自然实验组的指标就会一直坏下去,迟迟不见起色。
在前景不明朗的时候,老板不会同意你给新模型扩大流量。所以只能在线训练新模型的时候,给新模型自己产生的样本赋予更大的权重,希望新模型聚焦学习自己犯下的错误,改正离线训练时由于"冰山现象"带来的偏差。
最后,需要特别说明两点:
- 有的同学可能会问,照这么说,"冰山现象"算是推荐系统的一个大bug,为什么就没人把它解决掉呢?其实这也算是无奈之举。首先,未曝光的样本就没用用户反馈,本来就无法用于训练与评估。其次,越靠近冰山底部,数据越多,都要存储、计算的话,要消耗的资源也就越多。所以对精排,大家都约定俗成地用曝光数据做训练与评估了,其中的隐藏的"偏差”(bias)也就忽略不计了。
- 其实在推荐链路中离最终目标越远,这种"冰山现象"越严重,比如召回在线上预测时的候选集是全体物料,但在训练时即使使用了负采样,正负样本也都来源于有曝光的头部物料。又比如粗排在预测时的候选集本应该是召回的输出,但是目前大家都约定俗成使用曝光数据来训练与评估粗排模型。
# 解释一下“链路一致性”问题。你有没有遇到过“链路一致性”问题?如何解决的?
另一个可能造成"线上线下的实验结果不一致"的原因,来源于推荐链路各环节的不协调、不一致。离线实验中,我们都是基于用户真实反馈进行训练与评估。但是线上预测时,直接影响模型效果的,并非最终用户,而是链路下游的模型。这就好比,我(当前新模型)在一份方案中增加了一些新想法(改善推荐结果),但是这些新增内容不合我顶头上司(下游模型)的口味。顶头上司在向大老板(用户)提交方案时,将我的新想法删得一干二净。或许大老板喜欢我的新想法,但已经无所谓了,反正他也看不到,我的新想法不可能会有结果了。
举个例子,这次我新开发了一路"封面召回”,给用户返回与他之前点击的视频拥有类似封面的视频。但是由于粗排和精排还没有用上封面信息,所以在它们眼里,"封面召回"的视频与用户兴趣根本不搭边,从而将它们筛掉。"封面召回"最终有机会呈现给用户的结果寥寥无几,自然不可能在AB实验指标上体现出什么效果。
解决方法就是让模型不仅要拟合用户的兴趣爱好,还要迎合下游模型的口味。比如从未曝光的精排结果(也等同于被精排筛掉的粗排结果)中抽取一部分样本,构建Learning To Rank任务,辅助训练粗排模型,增强粗精排两个环节的一致性。
- 有什么办法评估特征有效性?
- 线上线下不一致问题碰到过吗?什么原因引起的?怎么解决的?
- 评价指标相关。auc是什么?为什么离线要用auc进行模型评估?auc是怎么计算的,写一个代码计算?其他一些排序指标比如ndcg也了解下。