# 在推荐系统中,一般的评估流程是什么样的?
在推荐系统中,一般的评估流程是
先进行离线评估。用相同的训练集,在相同的初始条件下(都随机初始化,或使用相同的初值),用不同算法,训练出新老两版模型。再拿这两版模型,在相同的测试集上进行评估。如果新模型的离线评估指标优于老模型,可以认为新模型通过了离线测试,可以进入下一阶段。出于快速迭代的考虑,离线评估中的训练集与测试集一般都不算太大,一般采用连续3天或7天的历史数据进行训练,在第4天或第8天的数据上进行测试。
第一步中离线训练得到的模型并不能直接上线使用。这是因为离线评估是在一个简单(训练集与测试集的规模都比较小)、理想(新老模型有相同的初始条件)的环境下进行的,但是实际线上环境却并非如此。离线评估中的新模型才用了几天的数据训练,而且已经停止更新,而线上正在运行的老模型已经在线持续更新了几个月,而且还在紧跟用户最新的兴趣变化而优化自己。此时我们手中的新模型,虽然被离线评估证明能力强,但是见识少,比如一些特征在离线实验的训练集中从未出现过,新模型在预测时只能以全0向量来代替这些特征的Embedding,但是线上的老模型见多识广,对这些特征的Embedding已经训练得相当充分了。拿这样"初出茅庐"的新模型上线,断然没有打败已经"久经考验"的线上老模型的可能性。所以,新模型在线之前,必须先回溯,比如自两周前的历史数据开始训练,直到追平并接入线上的实时样本流。之后,新老模型就能够同步接收线上最新的用户反馈来更新自己,才具备了公平进行/B实验的基础。
接下来,我们开始线上评估,也就是A/B实验。我们随机划分出两份流量,一份流量被称为"控制组"(Control Group,又称对照组)走老模型,另一份流量被称为"实验组"(Experiment Group)走新模型。实验一段时间后,统计两组流量上的关键业务指标(比如点击率、平均观看时长、平均销售额度等)。如果Experiment Group的指标"显著"优于Control Group,我们就认为新模型的确优于老模型,可以考虑推广至全部流量。
# 说一下AUC的物理含义
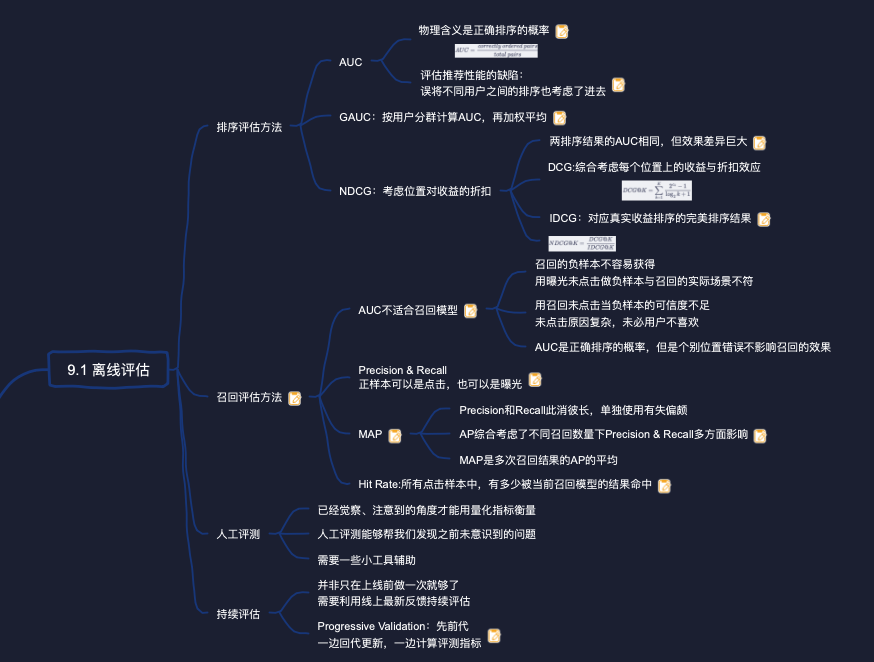
评估排序模型最重要(没有之一)的指标就是AUC (Area Under the Curve)。 AUC的概念是每个机器学习从业者都必须熟悉的。简单描述一下,给定一个划分正负类别的阚值,我们能统计模型在该阂值下的FalsePositive Rate (FPR)为横坐标,统计模型在该阚值下的True Positive Rate (TPR)为纵坐标,画一个点。通过变化阂值,这些点就连与一条ROC (Receiver Operating Characteristic) 曲线,ROC曲线与X轴围成的面积就是AUC,如图9-1所示。ROC曲线越向左上角靠拢,AUC越大,模型的分类性能越好。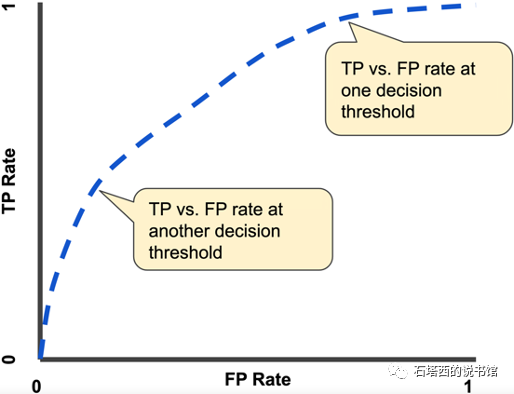
但是从面积的角度理解AUC太抽象,本节给出AUC另一种更为直观的解释:让模型给一堆样本(正负类别标签已知)打分,然后将这堆样本按模型打分从大到小排序,正样本能够正确地排在负样本前面的概率就是AUC。用数学表达,如下所示:
- 测试集中一个正样本与一个负样本,可以组成一对儿(pair)
- 分母就是能够组成的所有pair的个数
- 分子是正确排序,即正样本排在负样本前面的pair的个数
比如现在有三个正样本和三个负样本,按模型打分降序排列的结果如下图所示。其中一共有9对儿正负样本,有两对错误地将负样本排在了正样本前面,所以中的
从以上定义,我们可以看出,AUC就是为了衡量模型的排序性能而设计的。如果说一个模型的AUC=0.7,翻译成白话就是说,按这个模型的打分排序,有70%的概率能够将正样本排在负样本前面。
# AUC用在评价推荐性能时有什么缺陷?怎么改进?GAUC的计算方法?GAUC的缺点(提示:权重、位置)
推荐系统中的排序模型是为某个用户排序一系列物料,并不涉及给用户排序。所以,B用户的正负样本,在衡量模型对A用户的排序性能时,应该没有任何影响。而普通AUC将所有用户混为一谈,误将不同用户之间的排序也考虑了进去。
比如,现在有A和B两个用户,各自曝光了4个物料。8个样本根据模型打分,由高到低的排序是[A+,A+,A+,B-,B-,A-,B-,B+],其中A+和B+分别表示两个用户的正样本(比如点击的物料),A-和B-分别代表两个用户的负样本(比如曝光未点击的物料)。
- 根据公式,在全部8个样本组成的集合上,计算出全局
- 如果我们只看针对B用户的排序结果[B-,B-,B-,B+],正样本都排在了负样本后面,AUC=0,所以0.75的全局AUC高估了模型对B用户的排序能力。
从以上例子中可以看出,用AUC衡量推荐模型的排序性能会严重失真。解决办法就是改用Groupwise AUC(GAUC),也就是将测试样本划分为更小粒度的Group,每个Group统计一个AUC,再将不同Group的AUC加权平均,这样就能避免不同Group的样本相互干扰的问题。
具体到推荐场景,因为排序是针对一个用户的一次请求进行的,理论上我们也应该以"”一次请求"为粒度划分Group。但是这样做,一个Group中的样本太少,统计出来的AUC误差太大。所以在实践中,我们一般以用户为单位划分Group计算GAUC,如下所示。
根据公式,对于[A+,A+,A+,B-,B-,A-,B-,B+]这个例子,我们可以计算出
综上所述,GAUC是衡量排序模型性能的最重要指标。除了CTR、CVR这些二分类目标,对一些实数型目标(比如观看时长、销售金额),GAUC也同样适用:
- 一方面,推荐系统面对这些实数型目标时,常见作法是将它们转化为二分类目标。比如我们不直接预测时长,而是预测用户滑到某视频时是否会"有效播放”(比如观看超过15秒)、是否会"长播放”(比如观看超过1分钟)。转化为二分类目标后,GAUC就有了用武之地。
- 另一方面,我们在计算CTR的GAUC时,可以将公式中的用户权重u调整成用户观看时长;在计算CVR的GAUC时,可以将
# NDCG指标弥补了AUC的什么缺陷?NDCG的思路与计算方法。
物料在展示列表中的位置,对其能给用户、产品带来多少贡献,发挥着举足轻重的作用。排名越靠前,物料越容易被用户发现,用户的耐心也越充足,物料的价值越能充分发挥;反之,物料的位置越靠后,其价值也要大打折扣。而前面用AUC衡量排序性能的缺点,就在于其不能反映排序位置的这个"折扣"效应。
比如,假设在一个测试样本中,给用户展示了4个视频,用户点击了其中2个,一个看了10秒钟,另一个看了3分钟。两版模型对这个样本给出两种排序结果:
- 模型1的排序:
- 模型2的排序:
如果用AUC来衡量,两个排序结果都包含4组正负样本对,都只有一组正负样本排序错误(
或
的长视频放在3号那个不起眼的位置上,能否被用户看到都难说,那3分钟的时长贡献也就没了保证。
为了弥补AUC的这个缺陷,业界发明了Discounted Cumulative Gain(DCG)这个指标,综合考虑每个位
置上的物料能带来的收益和该位置的折扣效应,计算方式如下所示:
- K代表排序结果的长度
- 从分母上,我们可以看出,越靠后的位置,对物料价值打的折扣就越大。
但是不同推荐请求的结果长度不同,计算出来的DCG不好直接比较、汇总。为此,我们先定义Ideal DCG(DCG),即假设有一个完美的排序模型能够按各物料的真实贡献
假设有t1~t4四个物料,它们的贡献分别为{2,1,1,0}。模型给出的排序是
将多个排序结果的NDCG取平均,就可以衡量整个排序模型的性能。
# 为什么AUC不适用于召回模型?AUC能不能用于评价召回模型?
AUC指标不适用于衡量召回模型。原因有三:
- 计算AUC时,正样本容易获得,可以拿点击样本做正样本。但负样本从哪里来?照搬精排,用曝光未点击做负样本,行不行?不行。否则,测试样本都来自曝光物料,也就是线上系统筛选过的、比较匹配用户爱好的优质物料,这样的测试数据明显与召回的实际应用场景(海量的、和用户毫不相关的物料)有着天壤之别。失真的测试环境只能产生失真的指标,不能反映召回模型的真实水平。(读到这里,细心的读者会意识到,其实粗排也面临类似的问题。严格来讲,凡是曝光过的样本,对粗排来说,也应该算正样本。尽管如此,在实践中,我们仍然拿点击当正样本,拿曝光未点击当负样本,计算GAUC来评估粗排模型。大家都认为,在流程上,粗排比召回离精排更近,因此拿精排的标准来严格要求粗排,不算太离谱。)
- 那么拿召回结果中,除点击之外的其他物料当负样本,行不行?假设我们为一个用户召回了三个物料,按召回模型的打分降序排列分别为{A,B,C}。历史记录显示只有C被该用户点击过,算正样本。我们认为A和B是负样本,从而计算出AUC=0,是否合理?答案也是否定的。A、B未曾被用户点击过,可能是因为它俩从未向用户曝光过,所以我们不能肯定用户就一定不喜欢它俩,把A、B当负样本太过武断。
- 即便我们能够证明用户真的不喜欢A和B,从而计算出AUC=0,难道我们就能得出该召回模型毫于价值的结论?答案仍然是否定的。毕竟召回算法找到了用户喜欢的物料C,确实发挥了使用。至于C排名靠后,这一点根本不是问题。毕竟召回的顺序并非最终呈现给用户的顺序,把C的位置提前、筛选掉不招用户喜欢的A和B,那是粗排、精排的责任。
基于以上三点原因,在评估召回模型时,我们一般不用AUC这样强调排序性能的指标,也避免直接统计负样本,而是从预测正样本与真实正样本之间的"命中率”、"覆盖度"视角出发来进行评估。
# 如何使用Precision和Recal来评估召回模型的性能?
以评估双塔召回模型为例,评估样本的格式如下所示:
- 一条评估样本表示一次推荐请求及其结果,一共有N次请求
然后,我们计算
- K表示每次召回的物料的数量

注意在第11-12行,是用预测结果
型来说,曝光物料也应该算正样本。因此,也可以在第11~12行用曝光物料集合
Precision和Recall。最好将曝光样本与点击样本上的指标都计算出来,可以相互参考。
# 使用Precision和Recall作为召回评测指标存在什么问题?可以怎么改进?(MAP的思路与计算方法)
Precision和Recall是一对此消彼长的指标:召回的数量越多,Recall越大,Precision越小;反之召回数量越少,Precision越大,而Recall越小。既然Precision、Recall受召回数量的影响这么大,只采用单一个K值下的Precision和Recall来衡量模型的召回能力,未免有些偏颇,可能会一叶障目。
一个更加全面的衡量方法是,假设召回物料是按与用户的相关度降序排列的(这一点很容易做到),每次只取前i个作为召回结果返回,将不同i下的Precision、Recall连接成曲线,然后计算这个Precision-Recall曲线下的面积,被称为Average Precision(AP),如图9-3所示。要最大化AP,就需要在相同的Recall(X坐标)下,Precision(Y坐标)更高。所以,AP既综合考虑了不同召回数量的影响,也综合考虑了Precision/Recall两方面的影响,衡量角度更加全面,在评估召回模型时更加常用。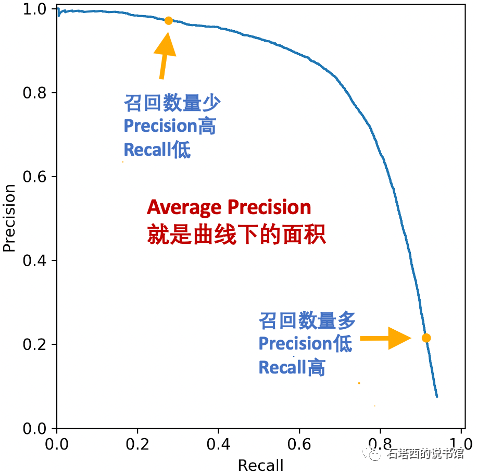
对于单一次召回结果,计算AP如下所示。
- K表示对于一次推荐请求,模型返回的最大召回数目。
- 分母Total Positives表示,历史样本中所记录的,在本次推荐结果中,用户喜欢的物料的数量。
- 分子中的Precision@j表示前j个召回结果的Precision。
- 分子中的IsPositive@j表示第j个召回结果是否为用户喜欢,喜欢的等于1,不喜欢的等于0。
AP只评估了单一一次召回结果,将多次召回的结果的AP取平均,就得到了MAP(Mean Average
Precision),就能用来衡量模型的整体召回性能。举个例子,假如召回模型一次性召回8个物料(即
K=8),现在有两条测试样本:
- 第1个用户点击了4个物料,都被模型召回了,其位置为{1,2,4,7},此次召回的
- 第2个用户点击了5个物料,但模型只召回了3个,其位置是{1,3,5},此次召回的
两次AP取平均,就得到该模型的
计算MAP的流程:
# 如何计算Hit Rate?
Hit Rate的计算方法与Precision和Recall类似,只不过将一条评估样本的单位由一次请求缩小到一条点击样
本,如下公式所示:
- 一条评估样本表示一条点击记录,一共有N条
Hit Rate表示在这N条点击记录中,有多少个
# 如何对召回结果进行人工检查?
各种离线评测方法都是围绕计算出一个指标来刻画模型的好坏,也就是量化的方法。但是也不要轻视、忽视亲自对推荐结果进行人工检查。各种量化指标虽然客观,但都是在我们已经注意到角度衡量模型。量化指标不能让我们对模型的推荐结果有最直观的感受,也就不能提示我们是否还有我们未曾意识到的、却能影响用户体验的因素。而人工检查能够弥补这一不足。
人工检查需要一些小工具,目的在于更直观地呈现推荐结果,帮助我们定位问题。可以开发一个帮助检查召回结果的工具,输入一个用户,工具并排显示两列结果。左边一列是用户近期观看视频的标题,右边一列是召回结果。从这两列中,我们能够看出很多问题,比如:
- 右列召回结果是否符合左列用户历史所反映的兴趣爱好?
- 假设左列反映出某个用户有个爱好,右列结果能覆盖其中几个爱好?
- 不同用户的右列结果,是否足够个性化?同质化是否严重?
Airbnb也开发过类似的工具,如下图所示,用来检查ltem-to-ltem(I2I)召回的结果。输入一个房屋的D,下边展示这个房屋的图片与介绍,右边列出模型召回的房屋的封面与介绍。人们可以通过这个工具检查召回的房屋与源房屋是否足够相似,从而对召回模型的性能表现有最直观的体验。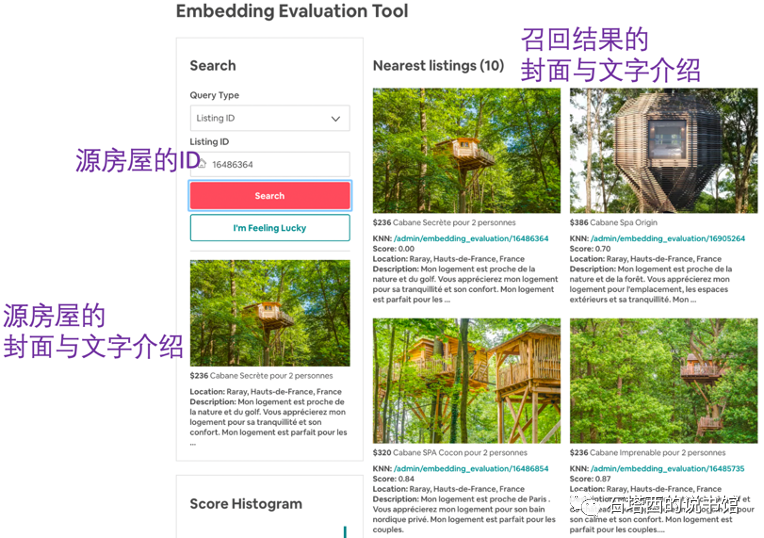
# 为什么要持续对模型进行评估?怎么评估?
模型评估并非只在模型上线前进行一次就完事了。如同模型需要利用线上最新的用户反馈持续更新一样,模型也需要持续评估。计算出当前最新的AUC、MAP等指标,并且在监控系统存储、汇总、展示,能够帮我们及早发现模型出现的问题(比如性能退化)。
笔者推荐使用Progressive Validation的方法进行持续评估。在这种方法中,模型拿到最新一批用户反馈后,先进行前代得到预测结果,接下来一边回代更新模型,同时拿预测结果与用户反馈真值计算各种评测指标。
Progressive Validation有两个优点:
- 在线训练与在线评估,共用前代环节,避免重复计算,也无须准备额外的测试数据
- 得到预测结果的时候,模型尚未被这些最新的用户反馈更新,所以基于这些预测结果计算出来的评估指标是无偏的,可信度更高。