
# 双塔模型在不同的场景中如何生成正样本?
双塔模型的应用场景非常广泛,在不同的场景中,可以用不同规则生成正样本。
- U2I召回:一个用户u与他交互过的物料t,相互匹配,可以构成一对正样本。
- I2l召回:一个用户在一个Session交互过的两个物料
- U2U召回:一个用户的一半行为历史,与同一个用户另一半的行为历史,都源于同一个用户的兴趣爱好,应该彼此相似,可以组成一对正样本。
# 双塔模型中Batch负采样的做法以及有什么优缺点?
互联网大厂在实践双塔召回时,一个常见作法是采取Batch内负采样。以点击场景下的U2l召回为例,
- 在一个Batch B中,第i条样本由用户
- Batch内负采样是指,除了
Batch内负采样如图所示。注意Batch内的每个用户向量,要与Batch内的每个物料向量做点积。这其实也是它的优点,由于w的某个负例t,的向量,已经作为u,的正例,被计算过了,可以被复用而避免重复计算。计算量的降低,对于面临”海量数据”和"模型实时更新”压力的各互联网大厂,是非常具有诱惑力的。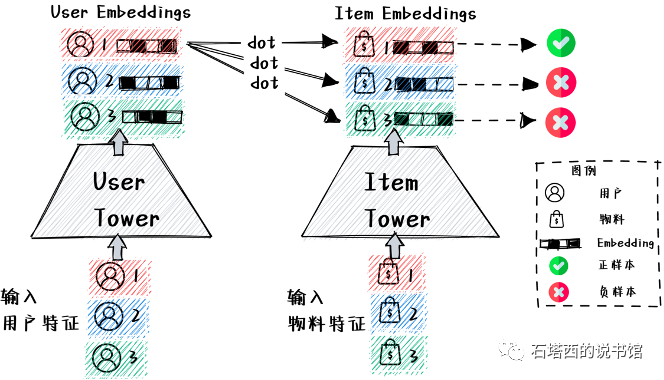
Batch内负采样的缺点是容易造成"样本选择偏差"(Sample Selection Bias, SSB)。这是因为,召回的正样本来自点击数据,而被点击的多是热门物料。再加上一个Batch的大小有限,其中的热门物料就更加集中,与召回要被应用于整个物料库的数据环境,差距较大。换句话说,Batch内负采样,采集到的负样本都是Hard Negative(大多数用户都喜欢热门物料),缺少与用户兴趣”八杆子打不着 的Easy Negative。
Batch内负采样还有以下几个优点:
- 训练速度快。batch内负采样样本少,因此训练速度快,迭代效率高。
- batch内负采样只需要增大batch_size就可以轻松让一条正样本见到足够多的负样本,从而很容易实现这个目标。
- 全库负采样一般采用sigmoid输出计算交叉熵作为loss,是一种point-wise loss,而batch内负采样的loss一般采用batch softmax,可以看成是对一个batch内的query、doc向量的叉乘后的矩阵做多分类任务,并且只对正样本的softmax值做CE,这其实是一种隐式的pair-wise loss。pair-wise比point-wise的优势在于引入了更多的比较信息,这是因为point-wise优化目标为:让正样本打分接近1,让负样本打分接近0;而pair-wise优化目标为:让正样本打分比其他所有负样本打分尽量高。
# 如何解决Batch内负采样的SSB(样本选择偏差)问题?
为了缓解"样本选择偏差"问题,Facebook、 Google和华为都在Batch内负采样的基础上发展了“混合负采样"(Mixed Negative Sampling)策略。混合负采样的作法,如图所示。
- 额外建立了一个"向量缓存",存储"物料塔"在训练过程中得到的最新的物料向量。
- 在训练每个Batch的时候,先进行Batch内负采样,同一个Batch内两条样本中的物料互为Hard Negative.
- 额外从"向量缓存"采样一些由"物料塔"计算好的之前的物料向量B',作为Easy Negative的Embedding。
尽管在一个Batch内部,热门物料比较集中,但是"向量缓存"汇集了多个Batch计算出的物料向量,从中还是能够采样到一些小众、冷门物料当Easy Negative的。所以,混合负采样对物料库的覆盖更加全面,更加符合负样本要让召回模型"开眼界、见世面"的一般原则。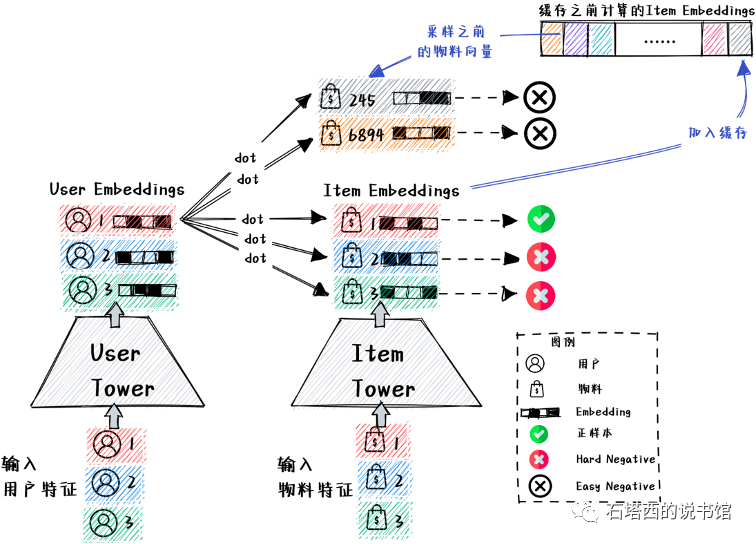
# 双塔结构有哪些显著的特点?
# 关于单塔
- 以U2I为例,用户特征喂入用户塔",输出用户向量;物料(无论正例还是负例)特征喂入"物料塔",输出物料向量。
- 塔的底座宽。不像ltem2Vec那样只能接受ltem ID当特征,双塔能够接受的特征大为丰富。用户侧可以包括:User ID、用户的人口属性(e.g.,性别、年龄)、用户画像(e.g.用户对某个标签的CTR)、用户各种行为历史(e.g.,点击序列)、物料侧可以包括:ltem ID、物料的基本属性(e.g.店铺、 品牌)、物料静态画像(e.g, 所属类别) ;物料动态画像(e.g.,过去1天的CTR),还可以包括由内容理解算法产生的各种文字、图像、音频、视频的向量。
- 塔身很高,每层的结构可以很复杂。这样一来, 底层喂入的丰富信息,在沿塔向上流动的过程中,可以完成充分而复杂的交叉,模型的表达能力相较于之前的Item2Vec、FM召回大为增强。
# 双塔一定要解耦
双塔的另一个特点在于"双"字。双塔模型要求两塔之间,绝对独立、解耦。只允许在生成最终的用户向量和物料向量之后,才点积交叉一次。在此之前,用户信息只能沿着"用户塔"向上流动,物料信息只能沿着"物料塔"向上流动。绝对不允许出现跨塔的信息交流,避免双塔勾连成单塔。
为了解耦,特征上,绝对不能使用任何交叉特征(比如,用户标签与当前物料的标签的重合度)。结构上,像Deep Interest Network那样,由候选物料对用户行为序列做Attention,也是做不到的。
# 用户行为序列是信息的重要来源,怎么接入必须要解耦的双塔模型呢?
用户的各种行为序列是反映用户兴趣的最重要的信息来源,如何将它们接入"用户塔",是业界研究的重要课题。最简单的如Youtube的作法,把用户过去观看的视频列表,先Embedding,再做Average Pooling聚合成一个向量,接入"用户塔"。
但是Average Pooling将用户的各个历史行为一视同仁,损失太多信息。我们还是希望能遵照Attention的方法,给每个历史行为赋以不同权重,在聚合过程中体现过轻重缓急。既然拿当前物料当Query做Attention违反了"双塔解耦"原则而行不通,业界提出了一些替代方案:
- 如果是在搜索场景下,用户输入的搜索文本是最能反映用户当下意图的,可以作为Attention中的Query,衡量用户各历史行为的重要性。
- 阿里的SDM召回中,使用用户画像当Query,给各历史行为打分。
- 微信的CDR模型,认为用户最后点击的物料,反映用户最新的兴趣偏好,可以当Query去衡量之前历史行为的重要性。
# 请简述双塔常用的损失函数,并说明有哪些技巧?
双塔模型比较常用的是基于Batch内负采样的Sampled Softmax Loss。 以U2l召回为例,双塔模型的Loss如公式所示。
- 第
、 、 、
# 双塔模型损失函数中的温度调整系数的作用是什么?
双塔模型损失函数中的温度调整系数
温度
- 如果
- 如果
# 双塔模型中的采样概率修正是怎么做的?
公式中的
如果我们使用"混合负采样",损失函数如下所示。
- 与上题中唯一的不同之处就是在生成负样本时,引入额外的负样本B,B代表之前生成的物料向量的缓存
因为现在负采样来自两种采样策略,因此