# 为什么类别特征在推荐系统中更受欢迎?
高维、稀疏的类别特征更加契合推荐系统的特点。 首先,推荐系统的基础是用户、物料画像。画像中的一级分类、标签都是类别特征,并且高维(比如一个推荐系统中有几万个标签是小意思) 、 稀疏(比如一篇文章至多包含那几万个标签中的十几个)。而且,为了增强推荐结果的个性化成分,互联网大厂都喜欢将User ID、ltem ID这种最细粒度的特征加入模型,显然这些特征都是类别特征,并且将特征空间的维度和稀疏性都提高了许多。 其次,推荐模型的输入特征与要拟合的目标之间鲜有线性关系,更多的是量变引起质变。举例来说,在电商场景下,我们希望建模用户年龄与其购买意愿、兴趣之间的关系。我们可以用数值特征来描述,特征叫"用户年龄",A用户的特征值是20, B用户的特征值是40。"用户年龄"在模型中对应个Embedding, 代表它对目标的贡献。使用时,拿特征值当成权重与特征Embedding相乘,表示对其贡献进行缩放。照这么说,年龄对B用户 的购买愿意的影响是对A用户的两倍?这个结论肯定是不能成立的。 显而易见的,不同年龄段(少年、青年、中年、老年)对购买意愿、兴趣的影响绝非线性,而是拥有各自不同的内涵,所以正确的方式应该是将每个年龄段视为独立的类别特征,要学习出自己的权重或Embedding。比如A用户使用的"青年"Embedding在向量空间中可能与一些价格适中、时尚爆款的商品接近,而B用户使用的"中年"Embedding可能与-些经典、单价高的商品接近,二者绝非向量长度相差一倍那种简单关系。
线上工程实现更偏爱类别特征,因为推荐系统中的类别特征超级稀疏,可以实现非零存储、排零计算,减少线上开销,提升在线预测与训练的实时性。以Logistic Regression (LR)为例,如公式(2-7)所示。
- 公式①使用了实数特征,公式②使用了类别特征。
- x是一条样本的特征向量,w是LR模型学习出来的权重向量,b是偏置项(bias)
- 如果使用实数特征,如公式①所示,需要进行很多乘法运算。
- 如果使用类别特征,如公式②所示,只需要将非零特征对应的权重相加即可,节省了乘法计算。而且由于特征空间的稀疏性,一条样本中的非零特征并不多,运算速度更快。
# 举例说明推荐系统中为类别特征而专门设计的技术。
第一,单个类别特征的表达能力弱,为了增强其表达能力,业界想出了两个办法
- 通过Embedding自动扩展其内涵。比如"用户年龄在20~30之间"这一个类别特征,既可能反映出用户经济实力有限,又可能反映出用户审美风格年轻、时尚。这一系列的潜台词,偏学术一点叫"隐语义",都可以借助Embedding自动学习出来,扩展了单个特征的内涵。
- 多特征交叉。比如单拿"用户年龄在20-30之间"这一个特征,推荐模型可能还猜不透用户的喜好。再交叉上"工作"特征,比如"用户年龄在20-30之间、工作是程序员",推荐模型立刻就明白了,"格子衬衫"对该用户或许是一个不错的选择。
第二,类别特征的维度特别高,几万个标签是小意思,再加上实数特征分桶、多维特征交叉,特征空间的维度轻轻松松就上亿,如果把User ID、Item ID也用作特征,特征空间上十亿都有可能打不住。要存储这么多特征的权重和Embedding向量,单机是容纳不下。于是,Parameter Server这样的架构应运而生,一方面Parameter Server利用分布式集群分散了参数存储、检索的压力,另一方面它利用了推荐系统的特征空间超级稀疏这一特点,每次计算时无须同步整个特征空间上亿特征的参数,大大降低了带宽资源与时间开销。
第三,类别特征本来就是稀疏的,"实 数特征离散化"和"多特征交叉"进一步 提高了特征空间的稀疏程度,从而降低了罕见特征的受训机会,导致模型训练不充分。为了解决这一问题,业界也想出了很多办法:
- FTRL这样的优化算法为每维特征自适立地调节学习率。常见特征受训机会多,步长小一些,防止因为某个异常样本的梯度一下子冲过头。罕见特征的受训机会少,步长可以大一些,允许利用有限的受训机会,快速收敛。
- 阿里的DIN为每个特征自适应地调节正则系数。
- 对第i个特征
# 说一说推荐系统中的类别特征映射原理。
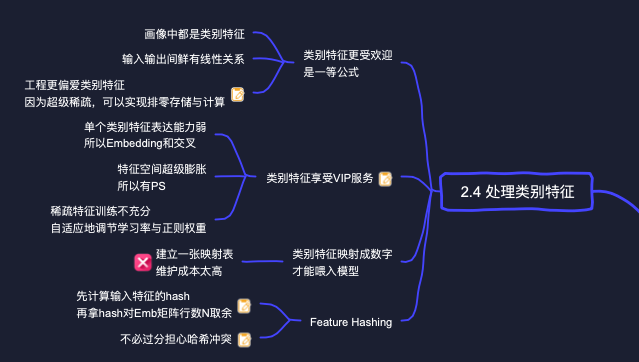
大家都知道文字是无法直接喂进模型当特征的,我们必须先将它们数字化。最简单的方法就是建立一张字符串到数字的映射表。
- 我们收集常见标签组成映射表,将标签映射成一个整数。
- 映射成的整数对应Embedding矩阵中的行号。通过这种形式,我们为每个标签查询得到它对应的Embedding向量。
- 接下来就是常规操作了,这些标签的Embedding向量Pooling成一个向量,喂入上层的DNN
 这种方式最大的缺点就是要额外维护一张映射表。就拿标签的映射表来说,随着时间推移,映射表要剔除老旧标签,添加新出现的标签,而且还要保证维护前后,相同的标签要能够映射得到相同的Embedding向量。其实标签还相对稳定,维护起来还比较容易,而对于User ID、 ltemID、交叉特征这些变化频繁的类别特征,维护映射表就成为极其繁重的负担。所以,映射表模式用在小型推荐系统中还可以,在大型推荐系统中可以使用”特征哈希”。
这种方式最大的缺点就是要额外维护一张映射表。就拿标签的映射表来说,随着时间推移,映射表要剔除老旧标签,添加新出现的标签,而且还要保证维护前后,相同的标签要能够映射得到相同的Embedding向量。其实标签还相对稳定,维护起来还比较容易,而对于User ID、 ltemID、交叉特征这些变化频繁的类别特征,维护映射表就成为极其繁重的负担。所以,映射表模式用在小型推荐系统中还可以,在大型推荐系统中可以使用”特征哈希”。
# 大型推荐系统通常采用的特征哈希的原理是什么?
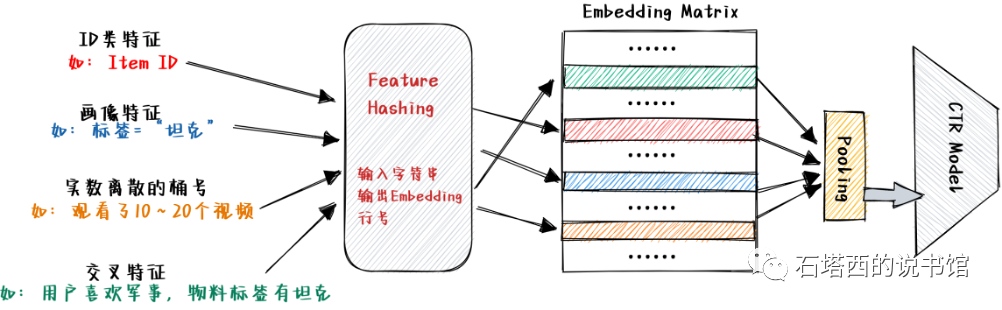
- Feature Hashing负责将输入的字符串映射成一个[0,N)之间的整数,N是Embedding矩阵的总行数,映射得到的整数代表该类别特征的Embedding在Embedding矩阵中的行号。
- Feature Hashing可以简单理解为,先计算输入的字符串的哈希值,再拿哈希值对Embedding矩阵行数N取余数。当然实际实现要更复杂一些,以减少发生"哈希冲突"(HashCollision)的可能性。
- 只要Embedding的长度相同,若干Field可以共享一个Feature Hash模块与背后的Embedding矩阵。相比于让各个Field拥有独立的Embedding矩阵,这种共享方式对空间的利用率更高,是大型推荐模型的主流作法。
# 特征哈希可能会存在哈希冲突的问题,会存在较大的负面影响吗?
细心的读者可能还是会担心发生"哈希冲突"的问题,也就是Feature Hashing将两个不同的特征映射到Embedding矩阵的同一行,从而这两个矩阵在训练与预测时被混淆,相互干扰。这种情况并不可能完全避免,但是问题也不大。 首先,哈希函数本身能够产生比较均匀的分布,冲突的可能性不大,冲突主要发生在第二步将哈希值压缩到[0,N)的时候。因此,只要我们将N选得大一些,就能够将发生冲突的概率控制住。 其次,由于推荐系统的特征空间是超级稀疏的,因此Feature Hashing造成的冲突是偶发的,而且影响有限。如果"哈希冲突"发生在两个罕见特征之间,毕竟影响的样本有限,冲突也就冲突了。
- 如果"哈希冲突"发生在一个常见特征与一个罕见特征之间,那个共享的特征Embedding大多数时间是被常见特征训练的,偶尔会被罕见特征带偏一下,但是也不会偏离太多。有点类似Dropout那种随机干扰,反而能够增强模型的鲁棒性。
- 如果"哈希冲突"发生在两个常见特征之间,一来这种可能性极低,二来只要我们加强对冲突指标的监控,这种冲突很容易被发现,而且只要我们在其中一个特征的字符串中添加一些前后缀,冲突就能解决。
总之,Feature Hashing简单易行,可扩展性好,尽管有发生冲突导致特征混淆的可能,但是这种可能性不大且负面影响可控,因此仍然是互联网大厂映射类别特征的标准手段。