# 你在建模行为序列中的每个元素时,一般会包含哪些信息?
以"用户最近观看的50个视频"这个序列为例。序列中每个元素的Embedding, 一般由以下几个部分拼接组成:
- 由每个视频的ID进行Embedding得到的向量。
- 时间差信息:计算观看该视频的时刻距离本次请求时刻之间的时间差,将这个时间差桶化成一个整数,再Embedding。这个时间差信息非常重要,序列中不同元素之间的相互影响,历史序列元素对当前候选物料之间的影响,肯定是随着彼此间隔时间而衰减的,因此我们必须将如此重要的信息喂入模型,方便模型刻画时间衰减。
- 以上两点是每个序列元素最重要的信息。除此之外,还可以加入观看视频的一些元信息(e.g, 视频的作者、来源、分类、标签等) 和动作的程度(e.g, 观看时长、观看完成度)
# 有哪些常用的pooling方法可以用于对用户行为序列进行压缩?
将一个用户的行为序列压缩成一个兴趣向量,最简单的方法就是进行如下按位(element-wise)操作:
简单Pooling提取出来的用户兴趣是固定的,不像接下来介绍的方法那样,能够随当前候选物料而变化。对于精排,这当然是个缺点。但是对于召回、粗排这种用户、物料必须解耦建模的场景,反正提取用户兴趣时也拿不到候选物料信息,简单Pooling仍然是最常见的选择。
# 简单Pooling存在什么问题?
简单Pooling的问题在于它将序列中的所有元素一视同仁,而在现实中,不同历史记忆对当下决策的影响程度并不相同。举个例子,一个用户过去买过泳衣和iPhone手机。
- 当被展示的商品是游泳镜时,用户是否点击,更多是出于他对买过泳衣的历史记忆。
- 当被展示蓝牙耳机时,过去购买iPhone的历史记忆将主导他此次是否会点击。换句话说,从用户行为序列中提取出来的兴趣向量,应该随当前候选物料的变化而变化,实现"千物千面"的效果
# DIN的建模思路是怎样的?怎么理解“千物千面”?
# 用户对于商品的兴趣有哪些特点?DIN是如何去捕捉用户兴趣的这些特点的?
多样性(Diversity):用户在访问电商网站时会对多种商品都感兴趣。也就是用户的兴趣非常的广泛,例如从一个年轻妈妈的历史行为中,可以看到她的兴趣非常广泛:羊毛衫、帆布包、耳环、童装、奶粉等等。
局部聚焦(Local Activation):即用户是否会点击推荐给他的某一件商品,往往是基于他之前的部分兴趣,而非所有兴趣。例如,对一个热爱游泳与吃零食的用户,推荐给他一个泳镜,他是否会点击与他之前购买过泳裤、泳衣等行为相关,但与他之前买过冰淇淋、旺仔牛仔等行为无关。
DIN针对当前候选广告局部地激活用户的历史兴趣,赋予和候选广告相关的历史兴趣更高的weight,从而实现Local Activation,而weight的多样性同时也实现了用户兴趣的多样性表达。
# 对于用户兴趣的捕捉,我们一般有哪些方法?
- 平等考虑所有的用户行为,对应到模型中就是使用average pooling层把用户交互过的所有商品的embedding向量取均值,从而得到用户向量。
- 按时间对用户做time decay,加大近期行为影响权重,具体在做average pooling的时候按时间调整权重
- 采用注意力机制,就是对不同行为特征赋予不同weight,这样某些weight高的特征便会主导这一次的预测,就好像模型对这些特征pay attention。
# DIN的输入是怎么处理的?
对于单值离散特征,经过Embedding Layer得到Embedding Vector。
对于多值离散特征,先经过一个Embedding Layer,后面增加一个Pooling Layer。Pooling可以用sum或average。最终得到一个固定长度的Embedding Vector,这是用户兴趣的一个抽象表示,常被称作User Representation,会损失一些信息。
# DIN的激活单元是如何设计的?
DIN会计算候选广告与用户最近N个历史行为商品的相关性权重weight,将其作为加权系数来对这N个行为商品的embeddings做sum pooling,用户兴趣正是由这个加权求和后的embedding来体现。具体地,AU 内部是一个简单的多层网络,输入是候选广告的embedding、历史行为商品的embedding、以及两者的叉乘。具体如下红框所示:

至于为什么增加叉乘作为输入?是因为两个embedding的叉乘是显示地反映了两者之间的相关性,加入后有助于更好学习weight。论文初版使用的是两个embedding差,经过了一系列的尝试和实验对比,才转为使用叉乘。
作者也尝试过 LSTM 结构实现AU,效果并不理想。理由是文本是在语法严格约束下的有序序列,而用户历史行为序列可能包含了多个同时存在的用户兴趣点,用户会在这些兴趣点之间“随意切换”,这使得这个序列并不是那么严格的“有序”,会产生一些噪声。
# DIN中使用激活函数Dice替代经典的PReLU激活函数,优势是什么?
PRelu是很常见的激活函数,其固定的折点(hard rectified point)是0:
f(s)=\begin{cases} s ,\quad if \quad s>0\\ \alpha s,\quad if \quad s≤0 \\ \end{cases} = p(s)s+(1-p(s))\alpha s
其中指示函数
论文对PRelu做了改进,使得曲线中间部分光滑变化,其中光滑的方式与数据分布有关:
常数
训练时,
Dice的主要动机是随数据分布变化动态地调整 rectified point,虽说是动态调整,其实它也把rectified point限定在了数据均值 ,实验显示对本文的应用场景Dice比PRelu效果更好。
# DIN使用了一种自适应正则,它的动机是什么?
使用自适应正则的出发点在于,使用的特征具有显著的“长尾效应”,即很多feature id只出现了几次,只有小部分feature id出现多次,这在训练过程中增加了很多噪声,并且加重了过拟合。
正则化是处理过拟合的常见技巧,但正则方法在稀疏数据深度学习上的使用,还没有一个公认的好方法。论文使用的特征具有显著的稀疏性,对绝大部分样本来说,很多特征都是0,只有很小一部分特征非0。但直接使用正则,不管特征是不是0都是要正则的,要梯度计算。对大规模的稀疏特征,参数规模也非常庞大(最大头的参数来源就是embedding),这种计算量是不可接受的。
论文提出了自适应正则,即每一次mini-batch,只在非0特征对应参数上计算L2正则(针对特征稀疏性),且正则强度与特征频次有关,频次越高正则强度越低,反之越高(针对特征长尾效应)。例如,在第m次mini-batch训练,对第 j 个特征的embedding向量
其中
# DIN论文中使用了GAUC作为评价指标,它的好处是什么?
AUC表示正样本得分比负样本得分高的概率。在CTR实际应用场景中,CTR预测常被用于对每个用户候选广告的排序。但是不同用户之间存在差异:有些用户天生就是点击率高。以往的评价指标对样本不区分用户地进行AUC的计算。
论文采用的GAUC实现了用户级别的AUC计算,在单个用户AUC的基础上,按照点击次数或展示次数进行加权平均,消除了用户偏差对模型的影响,更准确的描述了模型的表现效果:
其中权重w既可以是展示次数(impression)也可以是点击次数(clicks)。n是用户数量。
# 如果想在召回或粗排中建模用户长序列,怎么做?
DIN中的Attention需要拿候选物料t当Query,这在召回、粗排这些要求用户、物料解耦建模的场景是做不到的。这时,可以尝试拿用户行为序列中的最后一个物料当Query对整个行为序列Attention。 毕竟最后的行为反映用户最近的兴趣,可以当尺子衡量序列中其他历史物料的重要性。
# 为什么序列内的依赖关系是重要的?如何建模?
DIN实现了用户兴趣的"千物千面",但是仍有不足,就是它只刻画了候选物料与序列元素的交叉,却忽略了行为序列内部各元素之间的依赖关系。比如一个用户购买过MacBok和iPad,这两个历史行为的组合将产生非常强烈的信号,但是这种序列内部的交叉组合却末能在DIN中体现。为此,业界提出了一系列模型,使从行为序列中提取出来的用户兴趣向量,既能反映候选物料与历史记忆之间的相关性,又能反映不同历史记忆之间的依赖性。
第一步,用Multi-Head Self-Attention建模行为序列内部的依赖关系。Multi-Head Self-Attention的结果是一个与原始序列相同长度的新序列,新序列中的每个元素都以不同方式(i.e.,Multi-Head)融合了原始序列中其他物料的信息。
还举上面的例子,在原始用户行为序列中,"购买过Macbook"这一历史行为反映的只是单次购买本身。而对行为序列Self-Attention之后,同样的历史行为不仅反映了本次购买,还体现了2天前用户还购买过iPhone,和1天后用户又购买了iPad。通过与前后历史行为的交叉、关联,一个苹果忠实粉丝的形象跃然纸上。就这样,底层提取出来的用户兴趣的质量得以提高,上层的CTR建模自然也就降低了难度。
这里还可以像Transformer那样,叠加多层Self_Attention建模更深的特征交叉,但是那样做的计算开销也更大,通常一层Self-Attention足矣。
第二步,用当前候选物料和Self-Attention产生的新序列上套用DIN,建模候选物料与历史行为序列之间的相
关性,得到最终的用户兴趣向量。
# 计算一下Target Attention的时间复杂度,Self-Attention的时间复杂度
假设一个batch的大小为B,用户行为序列的长度为L,序列中每个Embedding的长度为d
- DIN中,拿候选物料当Query对整个序列做Attention时,
时 间 复 杂 度 - 双层Attention中,用户行为序列内部做Self-Attention的
时 间 复 杂 度
而推荐系统是有对用户长期行为序列建模的需求的。因为如果建模的序列太短,其中难免会包含一些用户临时起意的行为,算是一种噪声。另外,太短的行为序列也无法反映用户的一些周期性行为,比如每周、每月的习惯性采购。
# 每到“双十一”之类的促销季,用户的购买行为与他之前短期行为有较大不同,应该如何建模?
DIN是拿候选物料t对行为序列
既然在长序列上做Attention软过滤的代价太大,就干脆直接上硬过滤。在长序列中筛选(搜索)出与候选物料相关的一个短序列(一般长度在200以下),称为Sub user Behavior Sequence (SBS)。这个硬过滤的过程就是原文中的General Search Unit (GSU)。
由于长度大大缩短(万级→百级),在SBS再套用DIN就变得可行。拿候选物料t和SBS做Attention,加权平均后的结果就是用户长期兴趣的向量表达。这个过程就是原文中的Exact Search Unit (ESU)
而根据在General Search Unit中如何搜索,SIM又有Hard Search和Soft Search两种实现方式。
# 请简要讲述一下SIM中的Hard Search是怎么回事?
所谓HardSearch,就是拿候选物料t的某个属性(比如,物料分类或标签),在用户完整的长期历史中搜索与其有相同属性的历史物料,组成SBS。比如当前候选物料是一件衣服,SIM将该用户过去所有购买过的衣服挑选出来,组成针对这个候选物料的SBS。
当然,真正的搜索过程,不可能为每个候选物料都把用户全部历史都遍历一遍。为了加速这一过程,阿里特别设计了User BehaviorTree(UBT)数据库,将每个用户的长期行为序列,"分门别类"地缓存起来。UBT的结构如图4-11所示,类似一个双层的HashMap。
- 外层HashMap的key是UserId。
- 内层HashMap的key就是某个属性(比如,物料分类)。
- 内层HashMap的value就是某个用户在某个属性下的SBS。
这样一来,通过两层哈希查找,模型就能当前用户针对当前候选物料的SBS,效率足以满足线上预测与训练
的需要。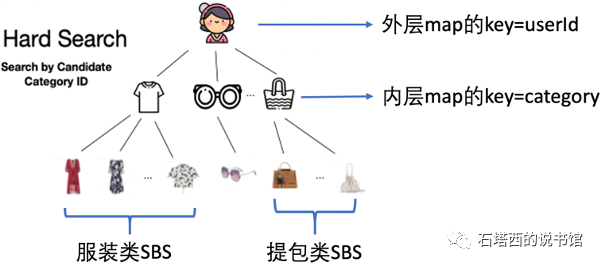
# 请简要讲述一下SIM中的Soft Search是怎么回事?
Hard Search是拿物料属性进行精确匹配,不如用Embedding进行"模糊查找"的扩展性好。于是,很自然想到用候选物料的ltem Embedding,在用户长期行为序列中通过"近似近邻搜索算法"(Approximate Nearest Neighbors,ANN),查找与之距离最近的前K个历史物料,组成SBS,这就是所谓的Sot Search。
至于ltem Embedding从何而来?原论文里,是只用候选物料和长期行为序列,构建了-个小模型预测CTR。模型训练完成后的复产品就是ltem Embedding。除此之外,用双塔召回粗排得到的Item Embedding行不行?用Word2vec算法套用在长期行为序列上得到的ltem Embedding,行不行?笔者觉得,理论上是没毛病的,都可以试一试,让离线指标和在线A/B testing的结果来告诉我们具体用哪种是最好的。
值得注意的是,SIM的论文里指出,用户长短期行为历史的数据分布差异较大,建模用户短期行为序列的ltem Embedding,不宜复用于建模用户长期行为序列。也就是说,同一个物料在用于建模用户长期兴趣与短期兴趣时,应该对应完全不同的ltem Embedding。基于同样的原因,如果你想用双塔模型的Item Embedding来进行Soft Search,你的双塔模型最好也拿长期行为序列来训练。如果嫌序列太长,拖慢双塔的速度,可以对长序列进行采样。
得到的Item Embedding之后,要喂入Faiss[22]这样的向量数据库,离线建立好索引(Search Index), 以加速线上预测和训练时的SoftSearch.
# SIM这种强而重的模型有什么局限?有什么改进方案吗?
虽然SIM模型提取出来的长期用户兴趣有"千物千面”的优点,但其缺点就是实现起来太过复杂,线上预测耗时增加得比较多。需要有工程团队的强有力配合,才能将在线预测和训练更新的耗时,降低到满足实时性要求。即便如此,一次请求中的候选物料也不能太多,因此SIM只适用于精排这种候选集有限的环节。
没有阿里那么强的工程架构能力,或者想在召回、粗排阶段引入用户长期兴趣,这时抄不了SIM的作业,怎么办?别急,除了阿里的"在线派"技术路线,我们可以离线将用户的长期兴趣挖掘好,缓存起来供线上模型调用。这种"离线派"技术路线,将费时的"挖掘用户长期兴趣"这一任务由线上转移到线下,省却了优化线上架构的麻烦,实现起来更加简单便捷。
一种方法就是人工统计长期兴趣。手工挖掘用户长期兴趣,在某些场合下代替SIM这种"“强但重"的模型。比如,我们可以统计出每个用户针对某个商品分类或视频标签,在过去1周、过去1个月等较长时段内的CTR,代表用户长期兴趣,喂进推荐模型。
另一种方法就是离线预训练一个辅助模型,提取用户长期兴趣。其一般流程是:
- 预训练该模型,输入用户长期行为序列,输出一个Embedding代表用户长期兴趣。训练好这个辅助模型之后,将行为序列超过一定长度的用户,都过一遍这个模型。得到代表这些用户长期兴趣的Embedding,存入Redis之类的KV数据库。
- 当线上预测或训练需要用户长期兴趣时,就拿用户的Userld检索Redis,得到代表他的长期兴趣的Embedding,喂入推荐主模型。
- 尽管用户一天之内会频繁动作,但是各用户的长期兴趣向量和生成它们的预训练模型,无须实时更新,只需要每天更新一次即可。因为用户刚刚发生的行为属于短期兴趣的建模范畴,留给DIN、双层Attention等模型去应付足矣。
美团建模超长用户行为序列,遵循的就是这种"离线派"技术路线。据说在美团场景下,取得了比SIM更好的效果[24]。
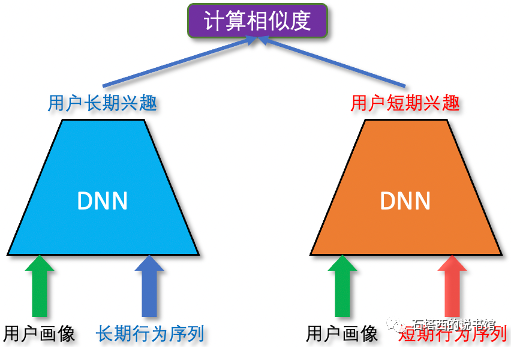
至于如何构建这样的预训练模型,一种方法是,用同一个用户的长期行为序列,预测他的短期行为序列,
如图所示:
- 模型采用双塔结构
- 喂入模型的样本是一个三元组(
- 建模目标是,同-用户的长短期兴趣向量应该相近,即
) - 双塔模型训练好之后,离线将老用户们的长期行为序列喂入左塔,就得到表示各用户长期兴趣的向量。
再次强调,“离线预训练用户长期兴趣"的作法,优点是不会增加线上耗时,实现简单;缺点就是得到的用户长期兴趣,不会随着候选物料而变化,无法做到"千物千面"。离线vs.在线,两种技术路线各有优劣,请读者根据自己的实际情况,权衡选择。
# 每个用户的行为序列长度不同,如何处理?Truncate很简单,关键是如何解决Padding的问题?
不解决的话,两个完全不同的序列,因为被填充的大量的0,而被模型认为相似
提示:可以看看TensorFlow Transformer的源码,看看人家是如何解决的?